K8S是如何知道程序是否是正常的?只要入口程序不退出,就认为是正常的。
什么是正常程序呢?就是EntryPoint指定的程序,更直观的说,就是在容器中PID=1的进程,就是入口程序,只要其还活着,K8S就认为这个程序是没问题的。
显然,这种方式太过简单,不能满足大多人的需要。
这里,K8S有了判断容器是否正常的机制,叫做健康检查。
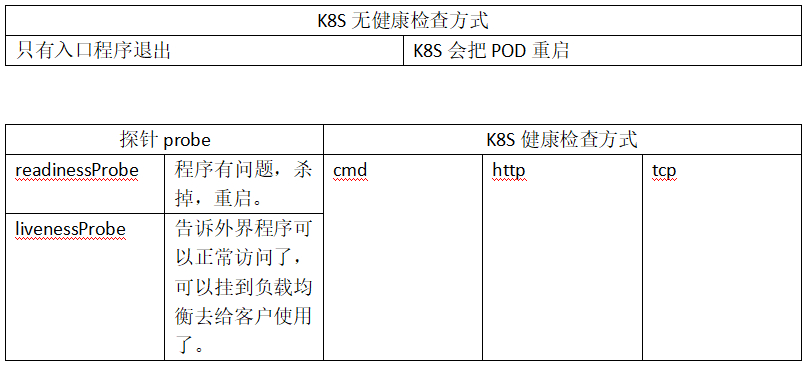
无健康检查
#先看下没有健康检查的情况下,K8S对程序的机制。
#K8S在无健康检查时,只有当入口程序退出时,在这种情况下,K8S才会把POD重启,其他情况不会重启。
#现有的这个web-demo就是没有健康检查的
[root@node-1 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
web-demo-67d9dcc6fc-kv4wx 1/1 Running 0 3m51s
web-demo-new-78cc59778d-dqmhn 1/1 Running 0 2m57s
#查看程序是否正常运行
[root@node-1 ~]# kubectl exec -it web-demo-67d9dcc6fc-kv4wx -n dev bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
bash-4.4# ps -ef
PID USER TIME COMMAND
1 root 0:00 sh /usr/local/tomcat/bin/start.sh
15 root 0:03 /usr/lib/jvm/java-1.7-openjdk/jre/bin/java -Djava.util.logging.config.file=/usr/local/tomcat/conf/logging.pro
16 root 0:00 tail -f /usr/local/tomcat/logs/catalina.out
60 root 0:00 bash
67 root 0:00 ps -ef
bash-4.4# netstat -lntup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 ::ffff:127.0.0.1:8005 :::* LISTEN 15/java
tcp 0 0 :::8009 :::* LISTEN 15/java
tcp 0 0 :::8080 :::* LISTEN 15/java
#杀掉这个PID=15的进程,发现进程已经没有了。
bash-4.4# kill 15
bash-4.4# ps -ef
PID USER TIME COMMAND
1 root 0:00 sh /usr/local/tomcat/bin/start.sh
16 root 0:00 tail -f /usr/local/tomcat/logs/catalina.out
60 root 0:00 bash
77 root 0:00 ps -ef
bash-4.4# netstat -lntup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
#当这个端口没有的时候,就不会往后端轮询了,会自动把这个服务排除掉,不会再负载均衡这个节点。
#但此时这个容器正常在运行
#此时KILL PID=1的进程,测试是否会退出容器
bash-4.4# ps -ef
PID USER TIME COMMAND
1 root 0:00 sh /usr/local/tomcat/bin/start.sh
16 root 0:00 tail -f /usr/local/tomcat/logs/catalina.out
60 root 0:00 bash
77 root 0:00 ps -ef
bash-4.4# kill 1
bash-4.4# ps -ef
PID USER TIME COMMAND
1 root 0:00 sh /usr/local/tomcat/bin/start.sh
16 root 0:00 tail -f /usr/local/tomcat/logs/catalina.out
60 root 0:00 bash
78 root 0:00 ps -ef
bash-4.4# kill -9 1
bash-4.4# ps -ef
PID USER TIME COMMAND
1 root 0:00 sh /usr/local/tomcat/bin/start.sh
16 root 0:00 tail -f /usr/local/tomcat/logs/catalina.out
60 root 0:00 bash
79 root 0:00 ps -ef
bash-4.4# cat /usr/local/tomcat/bin/start.sh
#!/bin/bash
sh /usr/local/tomcat/bin/startup.sh
tail -f /usr/local/tomcat/logs/catalina.out
#此时KILL PID=16的进程,会退出容器
bash-4.4# kill 16
#但还可以再进容器。
[root@node-1 ~]# kubectl exec -it web-demo-67d9dcc6fc-kv4wx -n dev bash
#发现进程又起来了
bash-4.4# ps -ef
PID USER TIME COMMAND
1 root 0:00 sh /usr/local/tomcat/bin/start.sh
13 root 0:03 /usr/lib/jvm/java-1.7-openjdk/jre/bin/java -Djava.util.logging.config.file=/usr/local/tomcat/conf/logging.pro
14 root 0:00 tail -f /usr/local/tomcat/logs/catalina.out
58 root 0:00 bash
65 root 0:00 ps -ef
#发现web-demo-67d9dcc6fc-kv4wx的RESTARTS=1,因为杀掉这个”catalina.out”入口程序结束/退出了。即:K8S在无健康检查时,只有当入口程序退出时,在这种情况下,K8S才会把POD重启,其他情况不会重启。
[root@node-1 ~]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
web-demo-67d9dcc6fc-kv4wx 1/1 Running 1 11m
web-demo-new-78cc59778d-dqmhn 1/1 Running 0 10m
健康检查方式(一):cmd配置
[root@node-1 deep-in-kubernetes]# mkdir 4-health-check
[root@node-1 deep-in-kubernetes]# cd 4-health-check
[root@node-1 4-health-check]# cat web-dev-cmd.yaml
#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: dev
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
#健康检查配置
#因为健康检查是针对于容器的,所以跟容器containers在同一级别。
livenessProbe:
#是否存活的探针,检查应用是否活着
exec:
#这里配置的检查方式是执行一个命令exec的command
#命令的内容是下述内容,当java进程存在,那么当前程序是存活的。
#那么是如何判断的呢?
#shell每执行一个命令都会有一个退出值,当退出值=0的时候,那么执行的这条命令是正确的/执行成功的,当退出值为非0的时候,那么执行这条命令是失败的。
#一旦执行失败,那么就会认为当前健康检查未通过,未通过的动作:POD重启。
command:
- /bin/sh
- -c
- ps -ef|grep java|grep -v grep
#以下为健康检查的数值配置
#执行这条命令的时候,等待容器启动10S之后再执行健康检查的命令。
#初始第一次检查的时间,一般设置到预计比程序启动的时间多一点。
initialDelaySeconds: 10
#健康检查的间隔10S。目的保证服务是可用的。非常重要的应用,那么间隔时间会短(性能消耗也大)。
periodSeconds: 10
#健康检查失败的门槛次数(这里是检查健康失败2次就放弃健康检查后直接重启这里的java进程)
failureThreshold: 2
#健康检查从错误到正确只需要成功一次,一旦发现java进程又存在了,那么就证明健康检查是存在的。
successThreshold: 1
#每次执行"ps java"命令(比如其他网络命令、其他检查类型命令,时间可能比较长,超市也是失败)的时候,最长的等待时间。
timeoutSeconds: 5
健康检查方式(一):cmd测试
[root@node-1 4-health-check]# kubectl apply -f web-dev-cmd.yaml
deployment.apps/web-demo created
[root@node-1 4-health-check]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
web-demo-7f9dbf65b4-r87z5 1/1 Running 0 15s
[root@node-1 4-health-check]# kubectl describe pods -n dev web-demo-7f9dbf65b4-r87z5
#多了健康检查的配置,说明生效了。
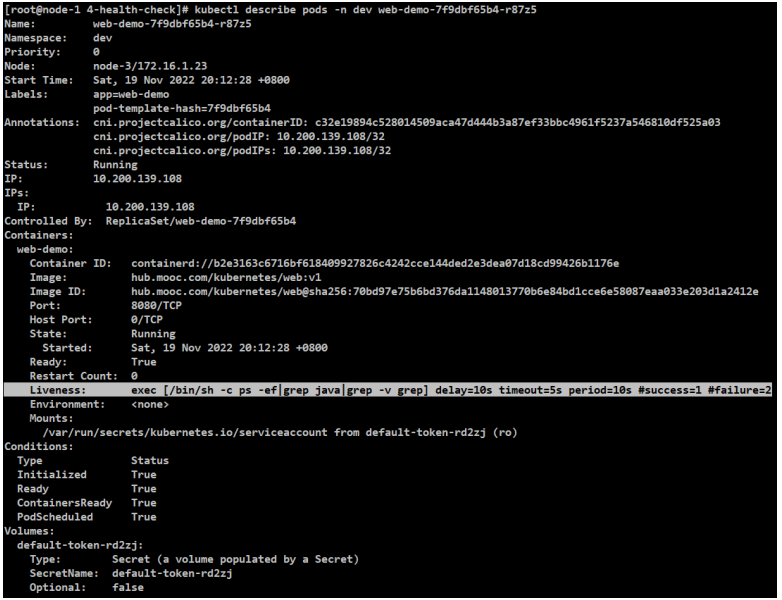
[root@node-1 4-health-check]# kubectl exec -it web-demo-7f9dbf65b4-r87z5 -n dev bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
bash-4.4# ps -ef
PID USER TIME COMMAND
1 root 0:00 sh /usr/local/tomcat/bin/start.sh
14 root 0:03 /usr/lib/jvm/java-1.7-openjdk/jre/bin/java -Djava.util.logging.config.file=/usr/local/tomcat/conf/logging.pro
15 root 0:00 tail -f /usr/local/tomcat/logs/catalina.out
202 root 0:00 bash
217 root 0:00 ps -ef
bash-4.4# ps -ef|grep java|grep -v grep
14 root 0:03 /usr/lib/jvm/java-1.7-openjdk/jre/bin/java -Djava.util.logging.config.file=/usr/local/tomcat/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djdk.tls.ephemeralDHKeySize=2048 -Djava.protocol.handler.pkgs=org.apache.catalina.webresources -Dignore.endorsed.dirs= -classpath /usr/local/tomcat/bin/bootstrap.jar:/usr/local/tomcat/bin/tomcat-juli.jar -Dcatalina.base=/usr/local/tomcat -Dcatalina.home=/usr/local/tomcat -Djava.io.tmpdir=/usr/local/tomcat/temp org.apache.catalina.startup.Bootstrap start
#测试刚才执行命令的结果。也可以用类似的情况。
bash-4.4# echo $?
#结果是0,说明健康检查程序是通过的。
0
#测试一个别的进程
bash-4.4# ps -ef|grep javaaa|grep -v grep
bash-4.4# echo $?
1
#command/cmd的这种健康检查就是通过这种机制去判断是失败还是成功的
#杀掉刚才的java进程
bash-4.4# kill 14
bash-4.4# ps -ef|grep java|grep -v grep
#稍等一会,因为健康检查是有时间的,这里设置的值并且要连续两次失败才是失败的。
#等了一会,发现exec的命令行自动退出了
bash-4.4# command terminated with exit code 137
[root@node-1 4-health-check]#
#发现这个POD已经RESTARTS=1了,说明健康检查连续两次发现java进程不在,把容器杀掉后重新启动了一个
[root@node-1 4-health-check]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
web-demo-7f9dbf65b4-r87z5 1/1 Running 1 8m18s
#再次核实事件
#确认是杀掉进程后重启
[root@node-1 4-health-check]# kubectl describe pods -n dev web-demo-7f9dbf65b4-r87z5

[root@node-1 4-health-check]# kubectl delete -f web-dev-cmd.yaml
deployment.apps "web-demo" deleted
[root@node-1 4-health-check]# kubectl get pods -n dev
No resources found in dev namespace.
健康检查方式(二):http配置
[root@node-1 4-health-check]# cat web-dev-http.yaml
#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: dev
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
#健康检查配置
#因为健康检查是针对于容器的,所以跟容器containers在同一级别。
livenessProbe:
#是否存活的探针,检查应用是否活着
#健康检查第二种方式:http。一定要找一个返回200的WEB页面(客户端能打开好测试)。
httpGet:
#应用要定期访问的路径。
path: /examples/index.html
#容器本身真实启动的端口!而不是应用和服务的端口!
port: 8080
#访问200才正常。其他失败。
scheme: HTTP
#以下为健康检查的数值配置
#执行这条命令的时候,等待容器启动10S之后再执行健康检查的命令。
#初始第一次检查的时间,一般设置到预计比程序启动的时间多一点。
initialDelaySeconds: 10
#健康检查的间隔5S。目的保证服务是可用的。非常重要的应用,那么间隔时间会短(性能消耗也大)。
periodSeconds: 5
#健康检查失败的门槛次数(这里是检查健康失败2次就放弃健康检查后直接重启这里的进程)
failureThreshold: 2
#健康检查从错误到正确只需要成功一次,一旦发现java进程又存在了,那么就证明健康检查是存在的。
successThreshold: 1
#每次执行HTTP访问的时候,最长的等待时间。
timeoutSeconds: 5
健康检查方式(二):http测试
[root@node-1 4-health-check]# kubectl apply -f web-dev-http.yaml
deployment.apps/web-demo created
#自己测试成功,也没有重启,describe也没有错误,但域名访问失败。
[root@node-1 4-health-check]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
web-demo-c9fbb6547-c8cjl 1/1 Running 0 2m4s
[root@node-1 4-health-check]# kubectl delete -f web-dev-http.yaml
deployment.apps "web-demo" deleted
[root@node-1 4-health-check]# kubectl get all -n dev
No resources found in dev namespace.
健康检查方式(三):tcp配置
[root@node-1 4-health-check]# cat web-dev-tcp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: dev
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
#健康检查配置
#因为健康检查是针对于容器的,所以跟容器containers在同一级别。
livenessProbe:
#是否存活的探针,检查应用是否活着
#第三种检查方式tcp:检查一个端口是否处于监听状态
tcpSocket:
port: 8080
#以下为健康检查的数值配置
#执行这条命令的时候,等待容器启动20S之后再执行健康检查的命令。
#初始第一次检查的时间,一般设置到预计比程序启动的时间多一点。
initialDelaySeconds: 20
#健康检查的间隔10S。目的保证服务是可用的。非常重要的应用,那么间隔时间会短(性能消耗也大)。
periodSeconds: 10
#健康检查失败的门槛次数(这里是检查健康失败2次就放弃健康检查后直接重启这里的进程)
failureThreshold: 2
#健康检查从错误到正确只需要成功一次,一旦发现java进程又存在了,那么就证明健康检查是存在的。
successThreshold: 1
#每次执行HTTP访问的时候,最长的等待时间。
timeoutSeconds: 5
健康检查方式(三):tcp测试
[root@node-1 4-health-check]# kubectl apply -f web-dev-tcp.yaml
deployment.apps/web-demo created
[root@node-1 4-health-check]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
web-demo-5db7d54c59-9ll62 1/1 Running 0 10s
[root@node-1 4-health-check]# kubectl delete -f web-dev-tcp.yaml
deployment.apps "web-demo" deleted
[root@node-1 4-health-check]# kubectl get all -n dev
No resources found in dev namespace.
探针与健康检查
问题:服务还未完全启动完成,就会被service发现,然后被调度到负载均衡上面去,不合理。
解决方案:比如,WEB程序一般会使用HTTP的方式。
[root@node-1 4-health-check]# cat web-dev-tcp2.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: dev
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 2
successThreshold: 1
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /examples/index.html
port: 8080
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 10
failureThreshold: 2
successThreshold: 1
timeoutSeconds: 5
[root@node-1 4-health-check]# kubectl apply -f web-dev-tcp2.yaml
deployment.apps/web-demo created
[root@node-1 4-health-check]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
web-demo-579d58cc8c-77kkp 1/1 Running 0 35s
#如果POD是ready,那么AVAILABLE就是1,否则AVAILABLE就是0。
[root@node-1 4-health-check]# kubectl get deploy -n dev
NAME READY UP-TO-DATE AVAILABLE AGE
web-demo 1/1 1 1 5m3s
[root@node-1 4-health-check]# kubectl delete -f web-dev-tcp.yaml
deployment.apps "web-demo" deleted
[root@node-1 5-scheduler]# kubectl get pods -n dev
No resources found in dev namespace.
其他
POD的状态未变成ready状态,那么就未通过健康检查。
那么ready这个探针就解决了服务是否可以对外访问的问题。
当容器出现restart时,怎么看待问题?
(1)如果是当频率比较低,几天几十天发生一次,可以把restart的策略从always改成never,当健康检查失败后,并不会重启,会把上线文保留下来,用于查询问题。
(2)如果是稳定复现/就是起不来的,通常会把livenessProbe去掉,或者简单的改成一个命令ls之类的,这样容器就不会被重启,就可以进去容器内去调试,就可以把它当成沙箱环境,做各种测试。
标题:Kubernetes(十)服务调度与编排(10.1)健康检查---高可用的守护者
作者:yazong
地址:https://blog.llyweb.com/articles/2022/11/22/1669062784655.html