概要
此文章基于快狗打车CEO-沈剑在”2021年5月29日Ocon软件大会第二天-百万司机在线打车平台架构演进”的演讲后做的个人总结。
一、分享内容的大概流程
1)创业初期,对技术团队与系统的要求?
项目初期,快速迭代。
2)快速发展期,对技术团队与系统的要求?
稳定性、扩展性、合理性
3)早期,系统不能突变。
如何搞定”快”与”稳定性、扩展性、合理性”的过渡演进?
二、目录结构
多业务-订单中心-系统统一过渡
高并发-经纬度检索-系统降压过渡
多场景-消息中心-系统抽象过渡
多策略-策略中心-系统解耦过渡
三、题外话
基于此次软件大会,可以发现一个很突出的特点,优秀的技术人员会把细节把控的很棒,并且很实用,及时总结,及时反思,及时落地,从不拖拉,严于利己,心胸阔达,热爱分享(一定要学好知识,为什么呢?一是自己要学好,二是要传播知识,传播文化,自己学好了才能不误人子弟。)。
四、演讲逻辑
首先说业务,然后说现阶段模式,接着说出现的问题/痛点与改进方式,达到一种什么效果,再接着说出现的问题/痛点(前面的流程线:循环渐进的说),最后做总结。
细致入微,把某个点说透,让别人知道架构怎么演进,而不是只是让别人觉得自己公司的架构很牛,而不能实现落地。
在这次大会中各个演讲者的差距很明显(不仅仅是技术),真正脚踏实地做技术的大牛仅占比20%左右。
一、 多业务 - 订单中心 -系统统一过渡
业务发展
早期业务:各自为战,闭环
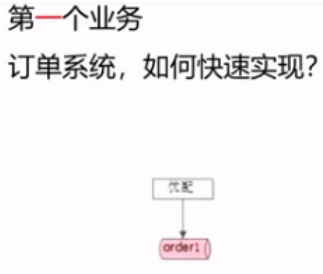
只有一个业务的情况下,体量是有限的,及业务量不大。
这个业务只设计一个订单表即可。写一个后台项目即可。
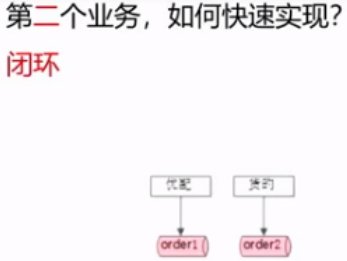
在第一个业务的基础上,新加一个库即可。
代码中不免会加入一些”if else”操作。
分析业务逻辑:
高频业务:小B商超老板卖(运)货
低频业务:C端搬家
长期 :订单中心要统一
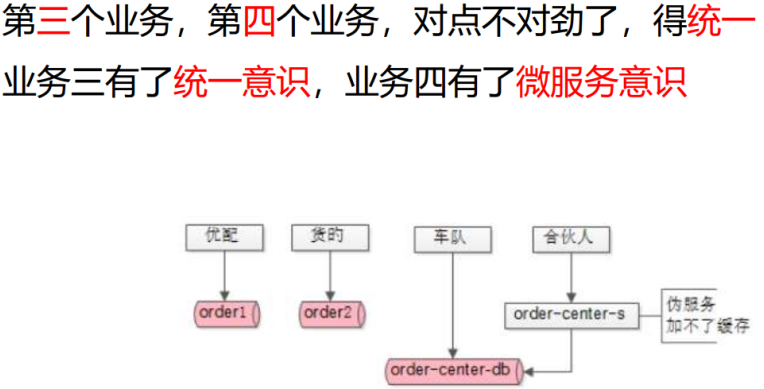
统一订单库 (数据收口)
疑问:是否要做统一的订单库。
那么此时要注意的是,一定要往未来的总的方向走。
案例:比如58同城网站的帖子、品类。每个贴子的属性都是不同的,房产和二手卖手机的属性不同。那么这个贴子是否分开做存储?
在第三个业务”车队业务”出现了,此时就要考虑是统一订单存储还是统一订单服务呢?不同的订单属性是不同的,也有相同的。结论:先统一库。当然,历史的订单库就不用了,慢慢迁过来,开发的新业务就用这个新库。
伪服务
传统架构会有各种耦合的问题。
随后出现了第四个业务等等。比如这里的合伙人业务,总体业务来说是大城市直营,还有分城市的团队。但小城市(三四线)订单体量可能比较小,招募合伙人,运营经验交给他,也就是城市合伙人,最后收入分成。那么,此时体量相对于以前单个业务或两三个业务来说就比较大了。
可以发现合伙人业务,接入了做了订单order-center-sevice微服务,直连数据库,但是现在是个伪服务,因为微服务有个特点,数据私有,任何人是不能绕过我的RPC接口去直接访问我后端的缓存和数据库的。
由于各种历史原因,车队业务是直接读取db的,合伙人业务是通过order-center-sevice读取db,会发现这个伪服务是加不了缓存的,因为order-center-db有写数据的变化,缓存的数据是没法得到通知和变化的。
(由于此伪服务案例可以引出的一个问题:调用方是否适合直接操作缓存数据?调用方不直接操作缓存数据,缓存统一由微服务层实施,微服务层向上游屏蔽底层复杂性,调用方像调用RPC本地服务一样去调用远程服务去拿数据,具体数据是从缓存中取的还是从数据库/mongodb/mysql/oracle/中取,以及数据库是否分库分表,调用方完全不关心,那么由此可以发现微服务的好处,微服务向上层屏蔽了底层复杂性。
所以可以总结一下,业务中的读写逻辑都在微服务做完统一数据库收口之后才能做缓存,收口之后,微服务自己知道怎样淘汰缓存,但如果调用方直接处理缓存,如果数据库的数据发生变化,那么调用方是没法获得通知的,可能出现数据不一致。)
由分到合的过渡
上述架构,是无法满足订单统一展现需求的,因为这个架构每个业务只能读取自己的订单,即只能读取一个订单中心列表,那么统一展现订单,上述的架构是实现不了的,如果必须统一展现各个业务的订单列表,比如货滴、车队的、合伙人的,就必须由APP统一访问多个库才能够实现订单的统一展现。那么此时可以发现,历史包袱是不能很快解决的。
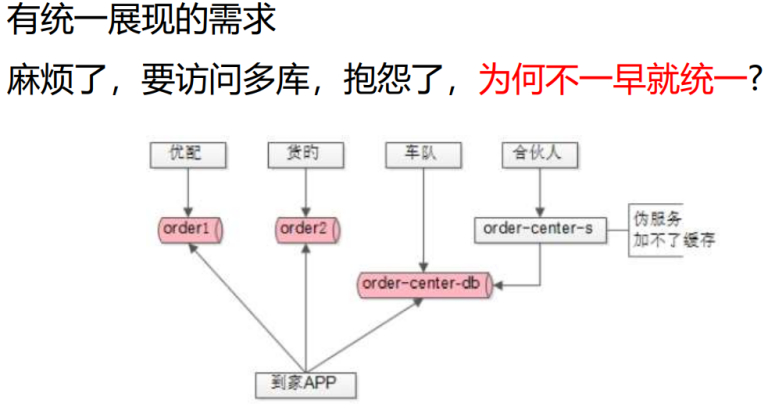
如何在不影响业务的前提下,做收口,做架构的演进。
做统一是合理的,问题转换为,怎么做统一呢?
有以下三个步骤可参考。
第一步:数据收口(尽量减少对原业务的影响)
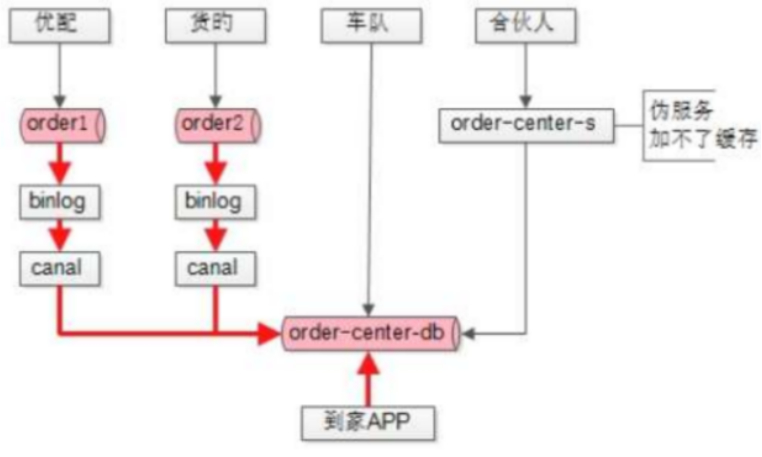
(注释:上图中加粗的红线是数据流向)
从上图可以发现优配和货滴原有的订单数据并没有汇总到新的库中,那么如果要同步数据,有下述几种改造方式:
一,可以业务侧做升级,双写,自己的订单库和新订单库,把自己订单的数据导入到订单中心,数据迁移后,下掉旧的库,改动量比较大。
二、所有业务不动,业务后端用工具canel、阿里云DTS、业务库的binlog,本质是数据的管道,进来是binlog类型数据,出去的数据处理可自定义,可以发现有一些属性不同,共性的部分对齐,个性的部分,通过扩展或JSON字段汇总到新的订单库。
最终,做了数据的收口,第一方便的是,订单列表可统一展现,不用访问多个库,而统一从收口的订单库可拉取所有的订单。
这是改造的第一步,但是此时还是会有业务不通过订单服务来直连数据库读写订单库,服务还是加不了缓存。所以在服务迁移的过程中,确实还需要做服务的改造。
第二步:服务收口(尽量支持分业务平滑过渡)
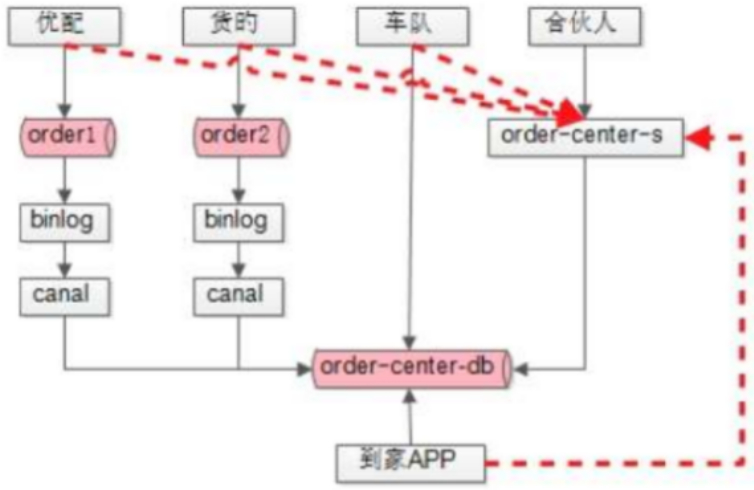
在服务的迁移过程中,确实需要在服务侧做改造,但是改造的成本相对于所有业务对数据库进行双写双读更小。
新订单中心order-center-service提供RPC接口,调接口时,传订单ID,返回订单实体,在未接入order-center-service以前,可能面对分库分表、缓存、JDBC等各种复杂性,此时,友好的RPC接口,让业务侧的升级更简单一些,那么这些业务全都访问order-center-service,以前APP读order-center-db,现在改到读order-center-service。order-center-service是可控的,可帮binlog做解析,同步到数据库。此时,所有的业务数据读写都收口到order-center-service,最终所有的数据都存入order-center-db,在第一步中,一些旧的DTS、binlog、canal等就可以下线了。
任何改造都是有时间成本的,这个改造的过程相对长一些。这个服务收口需要业务侧配合做改造,改造的周期可能是月级别,也可能是季度级别。
第三步:旧系统下线,完成统一
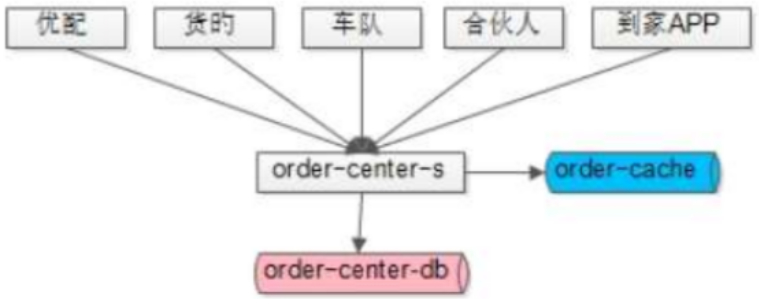
全部的服务收口做完后,才能在order-center-service增加缓存。
这个改造的周期可能是半年。
二、高并发-经纬度检索-系统降压过渡
业务简要:经纬度检索的特性为,客户搜距离最近的司机的经纬度,把订单推送给司机,派单或抢单,客户和司机都需要上报经纬度。
为什么二者要上报经纬度、检索经纬度?因为在同城的、实时的、及时的打车的业务中需要时时计算二者的距离,司机是不断变化的,要不断的上报,越频繁,系统压力越大。
初期,如何快速实现?
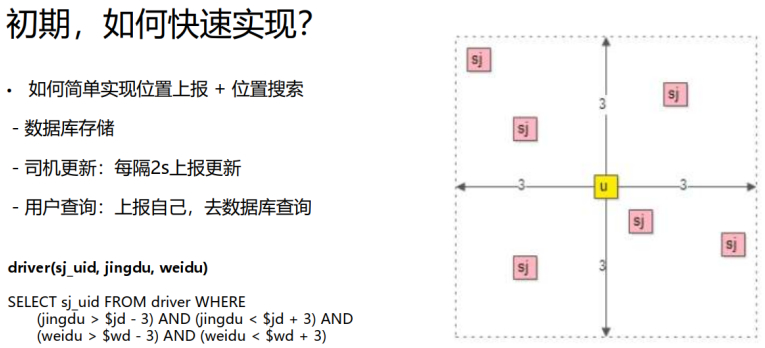
题外话:当有了想法之后,仅仅是一个点子,差不多两三天就上线了。到了后期,有了优化和改进的时候,说明业务就成功了,大部分创业团队到不了这个阶段就换下一个业务了。
那么此业务的逻辑是,客户搜3公里以内的司机,都要回捞出来。
在数据库中查询是,索引log(n)级别,做到了未全表扫描。(基于B+树)
注:在后期不断的改造过程中,可以发现,升级和优化不是突变的,而是一个逐步的过程。
降低数据库读写压力。
瓶颈一:数据库写压力大

当然这个早期的效率很低,当有100W在线司机之后呢?每2S上报一次经纬度,那么就意味着库的写入量是每秒50W次。
那么在业务的开发中,可以发现数据有很多大量无效的写入,即很多的经纬度并不会被用户查询到/读取到,那么这些数据就是无效的。
那么降压提效是合理的,怎么降压提效?
可以加缓存和异步线程,相当可控,但是损失了数据一致性和精准性。被查询的数据一致性也并没有那么高,丢个数据,差个100米,其实都还好。
瓶颈二:数据库查询性能低

写入效率上去之后,如何提升查询效率?可以发现随着业务的不断发展,查询效率比较低,O(log(n))。
短期
短期,可以通过倒排的方式进行改造。可以达到时间复杂度由O(log(n))到O(1)的过渡。
地图画成很多小格子,地理位置中很常用的方法。
最早是知道每个司机在哪个格子里(经度、纬度),倒排变为每个格子里有哪些司机,用格子建索引,格子的数据精度是可控的,比如距离几公里,不同粒度的格子提前建好,不同的格子里有不同的司机数据,这个时候,用户在下单的时候,回捞附近三五公里的司机的时候,就不像SQL语句(SQL语句本质上是在B+索引树上做查询,时间复杂度是O(lg(n))),那么用户上传经纬度,马上O(1)定位有哪些格子和司机,这些司机是潜在的,可指派和推送。如果该格子里的数据不够,扩大一圈召回,此时,时间复杂度的效率也是很高的,因为格子附近有哪些格子,时间复杂度O(1)是可以知道的,每个格子里有哪些司机,对应哪个司机ID的set值,也是时间复杂度O(1)查一个MAP就可以知道的)。
中长期
ES经纬的实时更新和检索,扛不住直接加节点即可,经线上验证,可经受的住百万量级的处理。
DB只存储司机的元数据信息。
三、 多场景 - 消息中心 - 系统抽象过渡演进
场景
端到云,云到端。发消息的需求。
系统到端上,端到系统发送一些信息。
端到端,通信,聊天需求。
第一个场景:端到云

注:端到云,云到端。发消息的需求。
每2s/5s把端上的数据通过GPS传给云端。
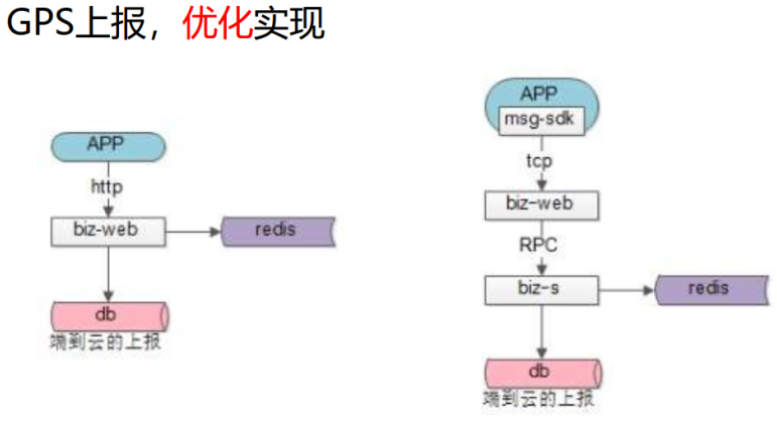
同前面场景涉及的RPC改造、微服务、缓存改造内容。
第二个场景:云到端
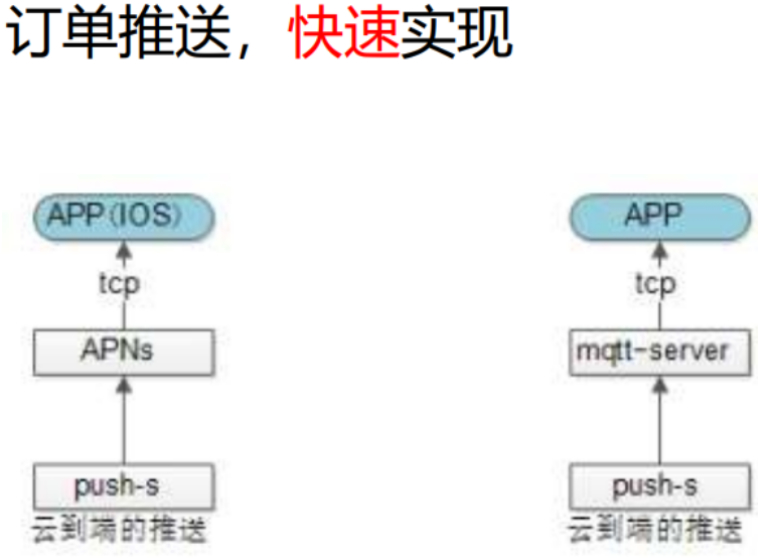
注:系统到端上,端到系统发送一些信息。
打车的业务场景,实时订单推送。客户下的单,要快速的推给附近的司机,让他们抢/做。(这是潜在消息需求)
常见的实现方式:
IOS的push。
ANDROID的自己搭建的开源MQTT。
第三个场景:端到端
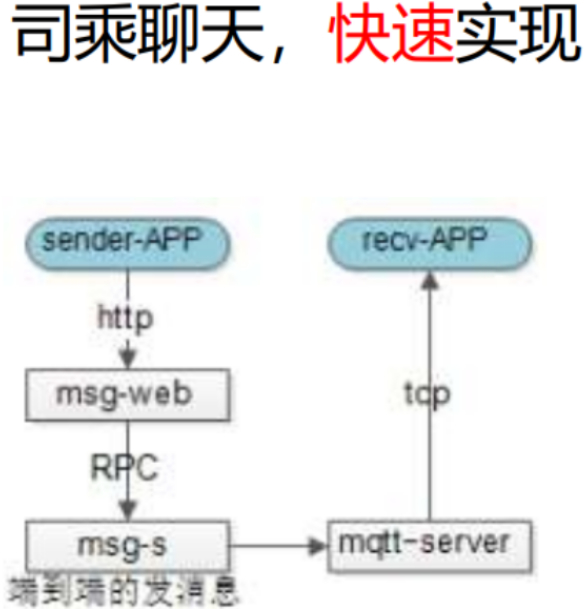
注:端到端,通信,聊天需求。
直接就根据早期的,结合端到云和云到端的功能来实现即可。
抽象消息通道
发现问题
此时可以发现,每个场景都要建立业务各自的消息通道,这个能否抽象成统一的通道呢?
在这个过程中有什么问题呢?新增一个业务,就新增了一个消息通道。
随着业务多起来,那么不同类型的消息通道就多起来,越来越复杂,如HTTP(效率很慢的)/TCP/MQTT/等。
消息通道是与业务没关系的技术。此时抽象出与业务无关的消息通道,实现不同端到云、云到端、端到端的需求。
如何抽象-消息中心抽象与统一
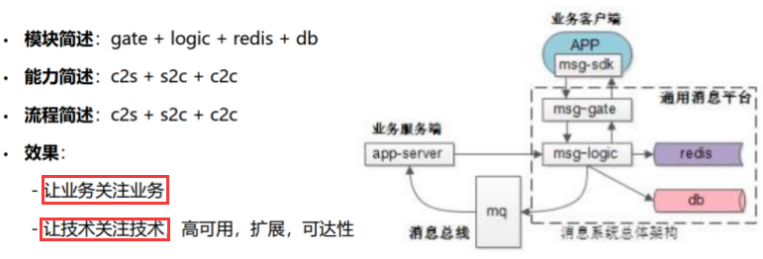
抽象是合理的,问题转换为,如何抽象?
虚线框内的子系统,为抽象的消息通道。可实现多类的业务需求,解耦各个子业务系统。
c2s即client to server;
s2c即server to client;
c2c即client to client;
第一、msg-gate作用:
1)维护与客户端的长连接;(APP与服务端建立TCP长连接,保证扩展性)
2)连接整流,对外一个APP,是一个长连接,100W司机同时在线,就是100W长连接。但对内部系统msg-logic不可能100W长连接,相对于服务连接池的10条20条(比如druid数据库连接池的配置),即:外部对客户端的100W条长连接变成内部的10条20条链接。
3)同时加解密(外网。信息安全。),安全信道,压缩解压缩(XML、文本信息)、初步的攻防、黑白名单、understanmu黑白名单、uid的黑白名单、IP的黑白名单、发包频率与速率的限制等。
第二、TCP的频繁升级怎么频繁过渡?
msg-gate是相对稳定的,不会频繁升级,功能只要实现之后,基本不会改动,动的是消息中转和业务的逻辑,发不同的消息内容与不同的消息处理。
维护与客户端的长连接的这些功能,基本上不会怎么动。即使要动,msg-gate服务端会给客户端发送通知,告诉新接入的外网IP消息,新消息连上来,新消息连新的连接,再断开老的连接,如要要频繁升级,那么这里的方法可能会比其他类视频、金融等业务的要容易一些。
第三、msg-gate很重要的功能是要保证可扩展性,这个是IM涉及的关键。
1)msg-logic要给某个司机发消息,怎么知道哪个司机连在哪个msg-gate上,用redis存储某一个用户某一个司机,对于消息系统而言,不管用户还是司机,只记录司机ID是否在线,如果司机ID在线,就知道司机ID连接在哪个msg-gate上,这是及时通讯系统与普通业务系统很不一样的地方。
2)msg-gate要保证扩展性,同一台msg-gate只能连接有限的司机,但是可以加msg-gate无线的机器数量来实现无限的司机同时在线。
3)要连接在哪个msg-gate上,msg-logic后面是业务系统,不管是订单推送/运营推送,推给某个司机,那么只需要知道司机ID和消息体,之后推给消息系统,msg-logic去redis中查这个司机连接在了哪一个msg-gate上,找到之后,msg-logic发消息,msg-gate与司机端建立了TCP长连接,把这个订单或运营消息发过去。
第四、最后,由此可知:
1)msg-logic是实现消息推送的业务逻辑中心。
高可用的redis存储司机是否在线,并知道在线的司机ID在哪个msg-gate上。
2)所有端到云c2s的业务,上报GPS,SDK将消息放给msg-gate,msg-gate给到msg-logic,msg-logic都通过MQ投递,不同业务订阅主题即可(消息是否成功msg-logic不需要等待的,直接投递,业务是否成功不关心,MQ做解耦,即msg-logic不会RPC调用消息的接收方)。
3)所有云到端s2c的业务:业务服务调用msg-logic的RPC接口,业务服务只需要提供ID、消息体即可,msg-logic负责投递。
4)最终的目的:关注消息的收发、处理、不需要关注整个消息的通道的扩展性、高可用。
四、 多策略 - 策略中心 - 系统解耦过渡
概要
1)捞取策略:附近几公里的司机,哪些该捞与不该捞,作弊的司机是否降权等。
2)推送策略:哪些司机先推、后推。
3)指派策略:滴滴的绝大部分场景是指派,58绝大部分为抢单,是因为货运与客运相比,标准化更难。
客运差异比较小,比如几个座位、豪华、中等。
那么货运,及其个性化需求,回单与回款、是否需要小拖车、小面、大小金杯、箱货,甚至不能用标签来穷举,甚至很多个性化需求要写在备注里。
58对于系统匹配还不够自信,比如完全系统来识别用户需求、司机所能提供的能力。
做一些比较粗的点来匹配,细的点让司机看备注,比如愿意搬货上楼的,就推送给司机,多个司机抢单举手,择优,中单。
当然还会有推送策略、中单策略、补贴策略、抢单策略、指派策略、AB策略、快速实施。
初期 ,如何快速实现
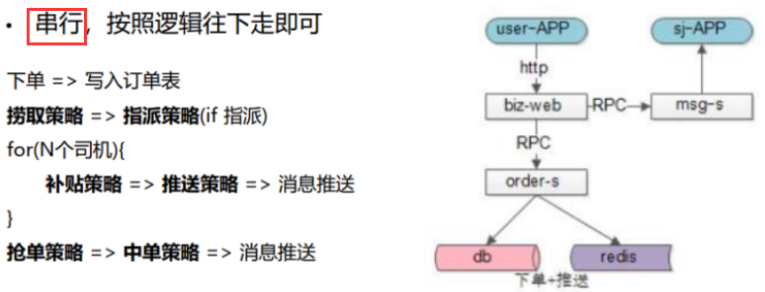
早期,基本上还是前面几个场景的模式,比如下单,大部分采取推送、抢单、中单的模式。
上述计算策略的逻辑执行完成之后,最终告诉用户,由某个司机匹配来接。
初期 ,如何快速优化
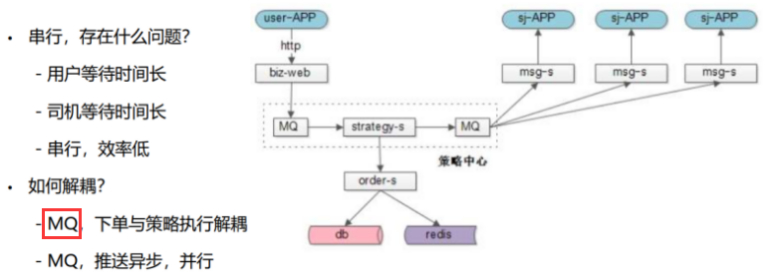
下单,系统提示返回成功不就行了,为什么还要等后续的操作(捞取、抢单等)?
对用户/司机而言,等待时间太长。
司机与客户端连接都是外网通信的,很可能最后一个第100个司机推送到的时候,30S已经过去了,可能第一个司机已经抢了,也可能已经中签了,这是系统问题导致的不公平。
所以用户不能等,司机要并行处理,比如可以加MQ解耦。
1)用户侧:下单和推送本身是两件不同的事情,推送成功与否,对用户下单不能影响,用户下单必须成功,加MQ解耦,发送,紧接着返回成功。
2)司机侧:策略的执行与推送也是无关的,多少个线程推,策略执行的系统并不关注。MQ做策略执行与消息推送的解耦。比如10个线程,推送给50个司机。
策略开发迭代频繁
非常多种策略,每种策略都有很多种方法,算法产品经理各种尝试,如改参数,加属性,权重调整。
如果每个策略有N种,且迭代频繁,把所有策略都放在一个服务service中,改动频率会非常高,写策略还有不同的团队。
比如推送策略、抢单策略、补贴而略等。
还可能出现,合代码、丢失、回滚、上线排队等问题。
策略如何解耦
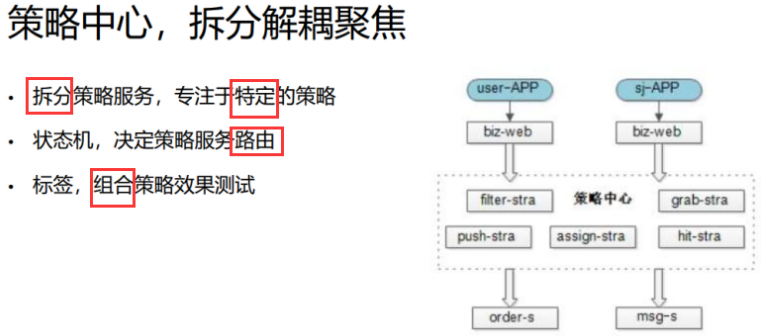
1)做拆分理论是合理的,垂直拆分是结构演进中非常常见的方法。解耦,拆分成不同的模块和服务,每个策略由不同的算法、产品、开发负责,迭代负责不同的模块。
2)同时,状态机决定策略服务之间的路由。
指派:只需要经过捞取策略路由到指派策略,这里没有推送、抢单、中单的过程。
有些是实时的抢单策略,可能先捞回,再推送,再计算补贴,再抢单,再中单,通过状态机的方式来进行路由,下个节点到哪个策略里,每路由到一个模块/实施一个策略,都打上一个标签,从日志里查询,这个标签可知这个订单的哪个策略用的哪个模型。这是一个串,好做AB侧,好做效果的区分,工具的收集,效果的展现,确定实验的策略,哪个策略是最好的,将流量覆盖到哪个补贴策略,哪个补贴策略的完单率最高,做算法和AB侧是需要这么做的,如果不用标签和状态机来路由,那么代码里一定是大量的”if else”。
五、 总结

标题:基于"百万司机在线打车平台架构演进"的分享总结
作者:yazong
地址:https://blog.llyweb.com/articles/2021/07/10/1625925367170.html