POD到底是限制资源使用呢还是不限制好?
如果限制,给多少CPU和内存合适呢?
从整个集群的市场来看,如何来规划资源的使用呢?
概要

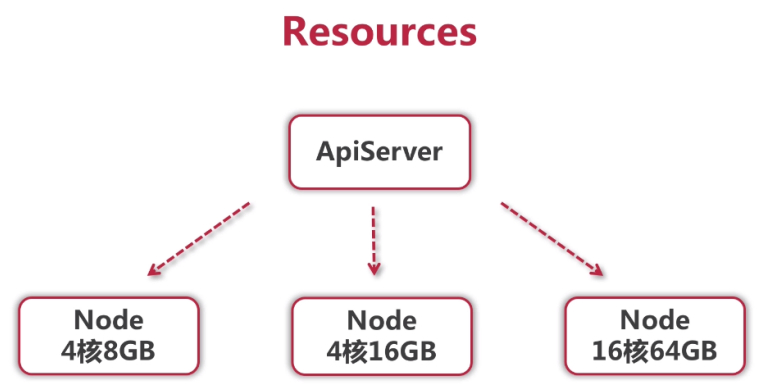
K8S集群中有很多node节点,这些节点的kubelet服务会收集这些节点的信息,上报给APISERVER,这些信息就包括了这些资源信息,多少CPU和内存。
比如现在想在K8S上跑一个服务,K8S怎么做呢?
最简单的,随便找一个节点,利用docker-run把它跑起来。如果这个程序需要20GB的内存,
把它调度到了16GB的内存的节点node-2,显然这个程序是起不来的,那么K8S最好事先知道这个程序占用多少内存,匹配这些节点有充足的内存,然后把这个程序调度到这个节点上,从而调度起来。跟我这个程序在同一个节点上的程序还可能有很多,跑了一段时间,这个程序触发了一个BUG,开始疯狂的吃内存,占用的内存越来越多,导致整个服务器的内存都用完了,所有的服务都起不来了,K8S看这样不行,太不稳定了,于是要给一个最高的限制,超过这个限制就杀掉,其他服务不会被连累到,这就是K8S资源限制的核心设计,一个是requests,一个是limits。CPU和内存都可以进行这两个参数的限制。

Requests:表示容器希望被分配到的可以被完全保证的资源量。作用:给调度器,调度器会使用这个值来参与它的调度策略的一系列计算,从而找到最优的节点。
Limits:容器能够使用的上限,当整个资源不足的时候,发生一些竞争的时候,会参考这个值,进行一些计算,从而做出进一步的决策,比如把谁给杀掉,这就是资源限制的策略。
和上一节的web-dev.yaml对比一下配置文件:
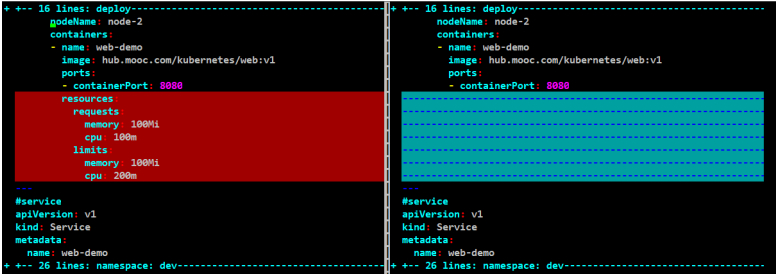
#内存单位是大写的Mi:不加单位默认是字节数。
#CPU单位是小写的m:如果不用单位的话,下述表示100个cpu,100个核心,加上单位m表示一核心的CPU等于1000m,这里100m表示0.1核的cpu。
#这里内存和CPU的配置都是绝对值。
resources:
requests:
#当前容器最少需要100M的内存,0.1核的CPU。
memory: 100Mi
cpu: 100m
limits:
#当前容器最大限制是使用100M的内存,0.2核的CPU。
memory: 100Mi
cpu: 200m
原始配置文件:web-dev.yaml
[root@node-1 2-resourse]# pwd
/root/deep-in-kubernetes/2-resourse
[root@node-1 2-resourse]# kubectl get all
No resources found in dev namespace.
#沿用上一节”/root/deep-in-kubernetes/1-namespace/web-dev”中的镜像。
#是此章节的web-dev.yaml生效
[root@node-1 2-resourse]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
web v1 0d9200b59e63 25 hours ago 162MB
hub.mooc.com/kubernetes/web v1 0d9200b59e63 25 hours ago 162MB
[root@node-1 2-resourse]# cat web-dev.yaml
#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: dev
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
nodeName: node-2
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
resources:
requests:
memory: 100Mi
cpu: 100m
limits:
memory: 100Mi
cpu: 200m
---
#service
apiVersion: v1
kind: Service
metadata:
name: web-demo
namespace: dev
spec:
ports:
- port: 80
protocol: TCP
targetPort: 8080
selector:
app: web-demo
type: ClusterIP
---
#ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web-demo
namespace: dev
spec:
rules:
- host: web-dev.mooc.com
http:
paths:
- path: /
backend:
serviceName: web-demo
servicePort: 80
[root@node-1 2-resourse]# kubectl apply -f web-dev.yaml
[root@node-1 2-resourse]# kubectl get all

[root@node-1 2-resourse]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-demo-5dd8485dc-hxr79 1/1 Running 0 14m 10.200.247.10 node-2 <none> <none>
查询资源配置
#关于资源的配置,其实可以事先知道所有的节点的目前剩余的资源。
#每台机器的CPU都为2核
[root@node-1/2/3 ~ ]# cat /proc/cpuinfo
2C
#每台机器的可用内存数
[root@node-1 ~]# free -mh
total used free shared buff/cache available
Mem: 6.1G 918M 4.3G 11M 925M 5.0G
Swap: 0B 0B 0B
[root@node-2 ~]# free -mh
total used free shared buff/cache available
Mem: 8.2G 1.6G 4.8G 105M 1.8G 6.3G
Swap: 0B 0B 0B
[root@node-3 ~]# free -mh
total used free shared buff/cache available
Mem: 6.6G 1.3G 3.7G 91M 1.6G 4.9G
Swap: 0B 0B 0B
#node-2机器
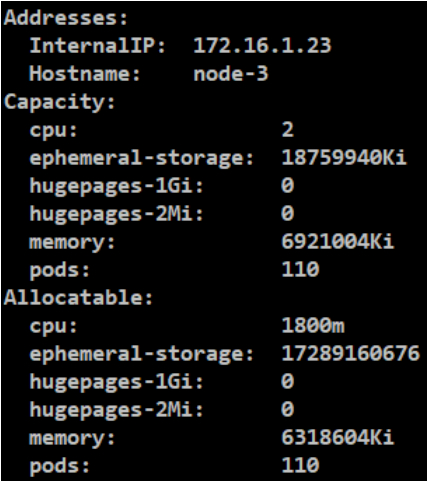
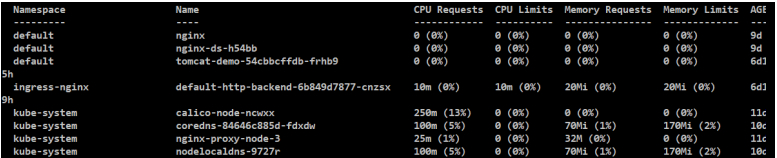
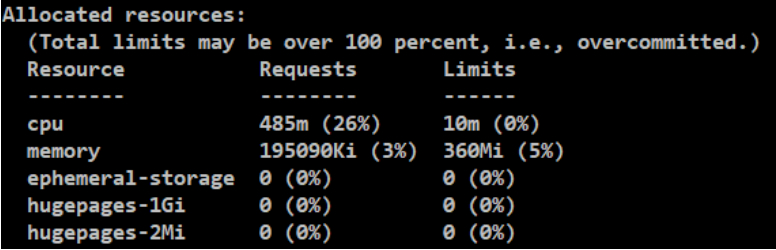
[root@node-1 2-resourse]# kubectl describe node node-2
#机器的资源(Capacity)和可以给其他服务分配的资源(Allocatable),因为会给系统预留一些资源,剩余给服务分配的资源。

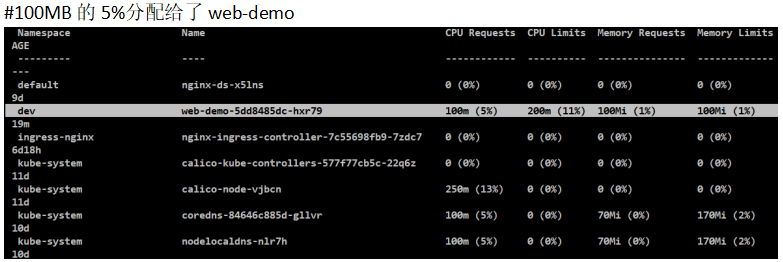
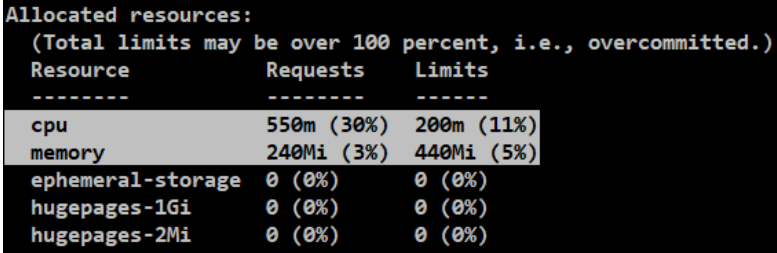
#node-3机器
[root@node-1 2-resourse]# kubectl describe node node-3
案例:调大limits内存(小于可用物理内存)
#比如内存比较小,如何调整
[root@node-1 2-resourse]# vim web-dev.yaml
原始内容:
resources:
requests:
memory: 100Mi
cpu: 100m
limits:
memory: 100Mi
cpu: 200m
修改内容:
resources:
requests:
memory: 500Mi
cpu: 100m
limits:
memory: 1000Mi
cpu: 200m
#生成新配置的服务
[root@node-1 2-resourse]# kubectl apply -f web-dev.yaml
#发现POD的创建和消亡过程。一个旧的停止,一个新的起来。
[root@node-1 2-resourse]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
web-demo-5dd8485dc-hxr79 1/1 Running 0 45m
[root@node-1 2-resourse]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
web-demo-5dd8485dc-hxr79 1/1 Running 0 48m
web-demo-5f6cc5668d-bd4lg 0/1 ContainerCreating 0 1s
[root@node-1 2-resourse]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
web-demo-5dd8485dc-hxr79 1/1 Terminating 0 48m
web-demo-5f6cc5668d-bd4lg 1/1 Running 0 5s
[root@node-1 2-resourse]# kubectl get pods -n dev
NAME READY STATUS RESTARTS AGE
web-demo-5f6cc5668d-bd4lg 1/1 Running 0 3m49s
解析containerd参数(接上)
为啥修改资源大小,需要要重启containerd呢?因为这个设置的本身就是依赖的containerd的隔离机制,需要重新启动一个containerd,才可以把这些隔离机制的参数加上去,既然使用了containerd,就看一下这些限制跟containerd的哪些参数是对应的。
[root@node-2 ~]# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
ababd205c903c 0d9200b59e63a About an hour ago Running web-demo 0 7c851d145c7a2
[root@node-2 ~]# crictl inspect ababd205c903c
#查看containerd参数设置
"linux": {
"resources": {
"cpu_period": 100000,
"cpu_quota": 20000,
"cpu_shares": 102,
"memory_limit_in_bytes": 1048576000,
(1)"cpu_shares"从对K8S的配置里面,requests.cpu这个值配置的是100Mi,先会把这个值转化为0.1核,然后再乘以1024,就等于102.4,就把这个值作为"cpu_shares"的值传给containerd,这个值在containerd里面是一个相对的权重,它的作用是决定在containerd发生资源竞争的时候,分配给容器资源的比例。比如有两个容器,requests.cpu分别设置为1和2,然后containerd运行起来,那么这个"cpu_shares"的值就分别是1024和2048,当这个节点发生资源竞争的时候,containerd会尝试按1比2的比例,将这个CPU分配给这俩容器,是相对的,当这个节点发生资源竞争的时候,用来决定资源分配比例的这样一个参数。
(2)"memory_limit_in_bytes",这里是1000M,对应requests.limits。
这个值除以1024再除以1024=1000Mi.
说明containerd在运行的时候,直接指定了这个内存为requests.limits的值。
(3)"cpu_quota"是在limits.cpu中做的设置,可以最大使用的CPU核心数,limits.cpu设置的是200m,单位是微秒,需要通过0.2核再乘以"cpu_period"的100000,就是这里的20000。
(4)"cpu_period"是containerd的默认值,单位是微秒,转换成ms就是,100ms。
(这里作者讲错单位了,默认值说成了纳秒)
(1s=10^3ms(毫秒)=10^6μs(微秒)=10^9ns(纳秒)=10^12ps(皮秒)=10^15fs(飞秒)=10^18as(阿秒)=10^21zm(仄秒)=10^24ym(幺秒))
"cpu_quota"和"cpu_period"这俩值是一对使用的值。表示在100ms内,最多给这个容器的CPU的量是这些。
案例:(压测)消耗POD所有内存(进程会被杀掉)(接上)
#这里尝试修改limits和requests,测试一下调度策略是啥样的。
#当这个容器有某些进程占用内存过大的时候,K8S会把容器里面占用内存最大的进程给杀掉,而不是说一定要把容器重启。
#CPU跟内存不同的是,进程不会被杀掉。
#为啥呢?因为CPU是可压缩资源,而memory不是,这就是CPU和内存的一些区别。
[root@node-1 2-resourse]# vim web-dev.yaml
resources:
requests:
memory: 100Mi
cpu: 100m
limits:
memory: 100Mi
cpu: 200m
[root@node-1 2-resourse]# kubectl apply -f web-dev.yaml
#进到容器中
#如何测试内存呢,简单些个程序,让其吃下内存就可以了。
[root@node-2 ~]# crictl exec -it 12eb9301215ef bash
#字符串自己加自己,越来越大。
#每0.1s把字符串扩大两倍。
#测试一下是否会把POD的内存吃完。100Mi应该是挺快的。
bash-4.4# cat test.sh
#!/bin/bash
str="[root@node-2 ~]#"
while [ TRUE ]
do
str="$str$str"
echo "+++"
sleep 0.1
done
bash-4.4# sh test.sh
+++
+++
......
bash-4.4# ps -ef
#执行时看是否有sh test.sh进程
51 root 0:00 sh test.sh
72 root 0:00 sleep 0.1
......
+++
Killed
#这个进程跑了一会就被killed,但是看到容器并没有退出,
bash-4.4# ps -ef
PID USER TIME COMMAND
1 root 0:00 sh /usr/local/tomcat/bin/start.sh
15 root 0:00 tail -f /usr/local/tomcat/logs/catalina.out
#容器中的其他程序还在跑着,只有这个shell程序被杀掉了,说明K8S会把容器里面占用内存最大的进程给杀掉,而不是说一定要把容器重启。
[root@node-2 ~]# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
12eb9301215ef 0d9200b59e63a 26 minutes ago Running web-demo 0 8ab445763e0cd
案例:调大limits内存(大于可用内存)
#继续修改limits。现在所有的服务器都没这么大的资源配置。
[root@node-1 2-resourse]# vim web-dev.yaml
resources:
requests:
memory: 100Mi
cpu: 100m
limits:
#现在所有的机器都没有100Gi的内存和20核的CPU。
memory: 100Gi
cpu: 20000m
[root@node-1 2-resourse]# kubectl apply -f web-dev.yaml
#在node-2上被调度起来了。这就说明调度策略不依赖于limits的设置。
[root@node-1 2-resourse]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-demo-5859bf8d4b-q57hg 1/1 Running 0 7m57s 10.200.247.18 node-2 <none> <none>
案例:调大requests内存(大于可用内存)
#调整requests的memory,不修改上面的limits。
[root@node-1 2-resourse]# vim web-dev.yaml
resources:
requests:
memory: 20000Mi
cpu: 100m
limits:
memory: 100Gi
cpu: 20000m
[root@node-1 2-resourse]# kubectl apply -f web-dev.yaml
#这里会一直生成STATUS为OutOfmemory的进程
#会发现新的服务会一直处于pending状态,旧服务会是Running状态。因为并没有找到满足requests设置资源配置的节点,所以把requests的相关值改的特别大的时候就起不来了。
[root@node-1 2-resourse]# kubectl get pods -o wide
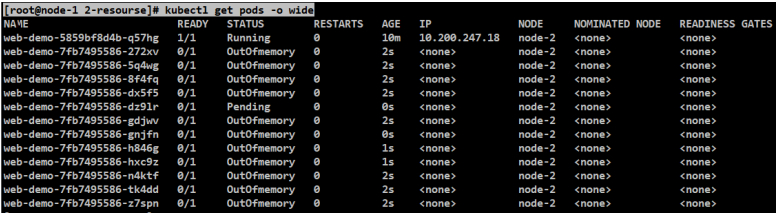
#但上一次启动的web-demo一直在node-2正常运行
[root@node-2 ~]# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
590d10deff84e 0d9200b59e63a 11 minutes ago Running web-demo 0 47e37c9f7ac68
#node-2的内存也正常
[root@node-2 ~]# free -mh
total used free shared buff/cache available
Mem: 8.2G 1.8G 4.6G 125M 1.8G 6.0G
Swap: 0B 0B 0B
#查看错误
[root@node-1 2-resourse]# kubectl describe pod web-demo-7fb7495586-dz91r -n dev

#最后手工杀掉进程。发现上次正常运行的web-demo也停止了。
[root@node-1 2-resourse]# kubectl delete -f web-dev.yaml
[root@node-1 2-resourse]# kubectl get pods -o wide
No resources found in dev namespace.
案例:调大requests-CPU(大于可用CPU)
#调整requests的cpu,不修改上面的limits。也一样处于pending状态。并没有满足cpu的要求。
[root@node-1 2-resourse]# vim web-dev.yaml
resources:
requests:
memory: 200Mi
cpu: 10000m
limits:
memory: 100Gi
cpu: 20000m
#测试内存改为200Mi,CPU改为10核。发现CPU超过了限制也是pending状态。
#这里会一直生成STATUS为OutOfcpu的进程
[root@node-1 2-resourse]# kubectl apply -f web-dev.yaml
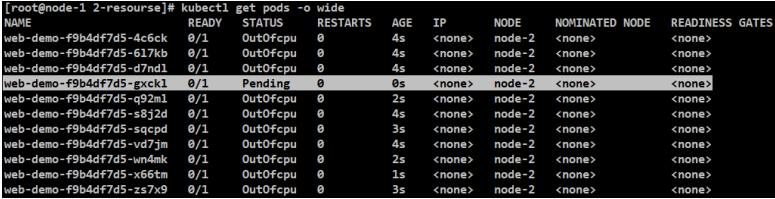
#在pending状态下,还可以通过kubectl看失败的原因
[root@node-1 2-resourse]# kubectl describe pod web-demo-f9b4df7d5-qcjp4 -n dev

[root@node-1 2-resourse]# kubectl delete -f web-dev.yaml
案例:调大requests内存(接近可用内存)
#测试内存的另一种情况,limits保持不动,改了requests.memory,现在我的每个机器还有将近5GB的内存。
[root@node-1 2-resourse]# free -mh
total used free shared buff/cache available
Mem: 6.1G 982M 4.2G 19M 1.0G 4.9G
Swap: 0B 0B 0B
[root@node-1 2-resourse]# vim web-dev.yaml
resources:
requests:
memory: 4Gi
cpu: 100m
limits:
memory: 100Gi
cpu: 20000m
[root@node-1 2-resourse]# kubectl apply -f web-dev.yaml
[root@node-1 2-resourse]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-demo-75c64b8fc4-v7z7s 1/1 Running 0 2s 10.200.247.19 node-2 <none> <none>
[root@node-2 ~]# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
00fd75c6ad733 0d9200b59e63a 23 seconds ago Running web-demo
案例:调整副本数(接上)
#再次调整副本数为3,3个实例是否都会运行起来。
[root@node-1 2-resourse]# vim web-dev.yaml
replicas: 3
resources:
requests:
memory: 3Gi
cpu: 100m
limits:
memory: 100Gi
cpu: 20000m
[root@node-1 2-resourse]# kubectl apply -f web-dev.yaml
[root@node-1 2-resourse]# kubectl get pods -o wide
#最终有两个服务运行起来了,另一个服务没运行起来。但node-2还有足够的资源把它跑起来,这就说明requests.memory是要预留出来的,虽然web-demo可能用了不到3Gi,但是requests.memory就得留出来,不能被其他服务占用掉,只能留着,这就导致了第三个实例没法跑起来的。
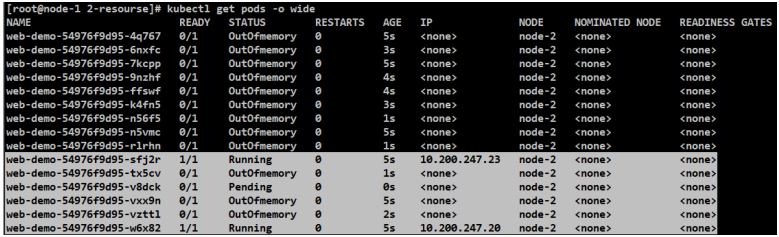
[root@node-2 ~]# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
bc8ac0ddb56ad 0d9200b59e63a 35 seconds ago Running web-demo 0 780caa1c903ed
7d8474e694f29 0d9200b59e63a 35 seconds ago Running web-demo 0 465e3abd6d9ca
[root@node-2 ~]# free -mh
#根据现有的内存值,上述三个示例都正常Running状态也可能。
total used free shared buff/cache available
Mem: 8.2G 2.0G 4.3G 133M 1.9G 5.8G
Swap: 0B 0B 0B
案例:(压测)消耗POD所有CPU(进程不会被杀掉)(接上)
#上面内存都测试完了,这里测试CPU。再去修改副本数为1。
#跟内存不同的是,这里测试时的进程不会被杀掉。
#为啥呢?因为CPU是可压缩资源,而memory不是,这就是CPU和内存的一些区别。
[root@node-1 2-resourse]# cat /proc/cpuinfo
2C
[root@node-1 2-resourse]# vim web-dev.yaml
replicas: 1
resources:
requests:
memory: 1Gi
cpu: 100m
limits:
memory: 100Gi
cpu: 2000m
[root@node-1 2-resourse]# kubectl apply -f web-dev.yaml
[root@node-1 2-resourse]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-demo-748f6fb565-xvwvc 1/1 Running 0 24s 10.200.139.90 node-3 <none> <none>
[root@node-3 harbor]# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
1d8ceddcea8a7 0d9200b59e63a 51 seconds ago Running web-demo 0 a26ffe2c8a193
[root@node-2 ~]# free -mh
total used free shared buff/cache available
Mem: 8.2G 2.0G 4.3G 133M 1.9G 5.8G
Swap: 0B 0B 0B
[root@node-3 harbor]# crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
1d8ceddcea8a7 0d9200b59e63a About a minute ago Running web-demo 0 a26ffe2c8a193
#动态查看CPU和内存的使用情况。
[root@node-3 harbor]# crictl stats 1d8ceddcea8a7
CONTAINER CPU % MEM DISK INODES
1d8ceddcea8a7 0.25 144.8MB 139.7kB 31
#在容器中模拟CPU占用,看CPU占用的效果。
输入输出,让其自己做一个循环,然后不断的给其加马力。
[root@node-3 ~]# crictl exec -it 1d8ceddcea8a7 bash
#加个马力
bash-4.4# dd if=/dev/zero of=/dev/null &
[1] 66
#第一个核满了
[root@node-3 harbor]# crictl stats 1d8ceddcea8a7
CONTAINER CPU % MEM DISK INODES
1d8ceddcea8a7 100.06 144.5MB 139.7kB 31
#再加一个马力,用到2核了。
bash-4.4# dd if=/dev/zero of=/dev/null &
[2] 67
[root@node-3 ~]# crictl exec -it 1d8ceddcea8a7 bash
CONTAINER CPU % MEM DISK INODES
1d8ceddcea8a7 193.15 144.5MB 139.7kB 31
#再加一个马力,还是2核。
bash-4.4# dd if=/dev/zero of=/dev/null &
[3] 68
[root@node-3 ~]# crictl exec -it 1d8ceddcea8a7 bash
CONTAINER CPU % MEM DISK INODES
1d8ceddcea8a7 189.11 144.6MB 139.7kB 31
#再加一个马力,还是2核。
#说明limits生效了,只给限制了2核的CPU。
#但是跟内存不同的是,进程不会被杀掉。
#为啥呢?因为CPU是可压缩资源,而memory不是,这就是CPU和内存的一些区别。
bash-4.4# dd if=/dev/zero of=/dev/null &
[4] 69
[root@node-3 ~]# crictl exec -it 1d8ceddcea8a7 bash
CONTAINER CPU % MEM DISK INODES
1d8ceddcea8a7 193.60 144.7MB 139.7kB 31
bash-4.4# ps -ef
PID USER TIME COMMAND
1 root 0:00 sh /usr/local/tomcat/bin/start.sh
15 root 0:03 /usr/lib/jvm/java-1.7-openjdk/jre/bin/java -Djava.util.logging.config.file=/usr/local/tomcat/conf/logging.pro
16 root 0:00 tail -f /usr/local/tomcat/logs/catalina.out
60 root 0:00 bash
66 root 0:28 dd if /dev/zero of /dev/null
67 root 0:21 dd if /dev/zero of /dev/null
68 root 0:15 dd if /dev/zero of /dev/null
69 root 0:13 dd if /dev/zero of /dev/null
70 root 0:00 ps -ef
#全都杀掉
bash-4.4# killall dd
[3]- Terminated dd if=/dev/zero of=/dev/null
[4]+ Terminated dd if=/dev/zero of=/dev/null
[1]- Terminated dd if=/dev/zero of=/dev/null
[2]+ Terminated dd if=/dev/zero of=/dev/null
bash-4.4# ps -ef
PID USER TIME COMMAND
1 root 0:00 sh /usr/local/tomcat/bin/start.sh
15 root 0:03 /usr/lib/jvm/java-1.7-openjdk/jre/bin/java -Djava.util.logging.config.file=/usr/local/tomcat/conf/logging.pro
16 root 0:00 tail -f /usr/local/tomcat/logs/catalina.out
60 root 0:00 bash
72 root 0:00 ps -ef
标题:Kubernetes(九)资源对象(9.2)Resources---多维度集群资源管理(上)
作者:yazong
地址:https://blog.llyweb.com/articles/2022/11/19/1668798818422.html