概要
Requests和Limits的设置还有几点比较重要。
Requests和Limits的值有关联的。
服务可靠性的等级,就用这俩值来区分的。
(1)这俩设置成一样的值,就说明这个服务是完全可靠的,等级最高的。
如果都没设置值,就说明服务是最不可靠的,并不建议,当没资源的时候,第一个被干掉的就是这个没设置的。
(2)limits>requests,比较可靠的服务,当出现资源竞争的时候,是按照优先级来Shutup。当出现CPU竞争的时候,是不会被杀掉的,CPU是可压缩资源,占用多了就少分点就行了,分多少呢就看request了。Request多就多分一些,跟limit没关系。
为什么K8S要根据requests和limits来自动判断服务等级呢???
(1)这样的策略虽然少了灵活性,但提高了稳定性,更加简单。
(2)重要的服务,要求requests和limits设置的一样,留给足够的资源,足够的资源就意味着服务的稳定。
(3)如果可以随意的设置服务的安全等级,就可能存在设置错误的情况,一个本该特别安全的服务,忘记设置了,那么资源就被别人抢占了。
这里就是requests和limits的设置,以及K8S判断服务的等级这样的一个关联关系。
设想两个场景:
(1)两个节点的内存都只有4Gi,如果requests设置5Gi,那么永远调度不起来。
(2)更普遍,资源足够的,但不能让任何人随便用,随便定义一个requests为100Gi,实际就用了1Gi,资源都被占用了,别人就用不了了。
(3)requests配置1Gi,limit配置100Gi,这样也不合理,内存波动实在太大了,没人知道到底要用多少内存。
所以为了防止类似上述不合理或者错误的方案的产生,K8S给出了一种方案叫做limit range,它也是一种资源,也是通过一个配置文件来描述的。
方案一:limit range
#属性limits与命名空间namespace
#测试一下这里的设置。
[root@node-1 2-resourse]# kubectl create ns test
namespace/test created
#新建一个namespace,因为limits是对一个namespace而言的,在一个namespace下面,可能来设置这些限制、默认值。
原始配置文件:limits-test.yaml
[root@node-1 2-resourse]# cat limits-test.yaml
apiVersion: v1
#kind为limitRange,是一个范围的限制。
kind: LimitRange
metadata:
name: test-limits
spec:
#下述是对POD的限制
limits:
- max:
cpu: 4000m
memory: 2Gi
min:
cpu: 100m
memory: 100Mi
maxLimitRequestRatio:
cpu: 3
#Requests和limits的比值最大不能超过3,意思是同一个配置里,CPU的limits最大可以比CPU的requests大3倍,不能在大了,否则不能创建成功。
memory: 2
type: Pod
#上述是对POD的限制
#下述是对容器Container的限制
- default:
#这里default默认值就是limit。
cpu: 300m
memory: 200Mi
defaultRequest:
#这里defaultRequest默认值就是request。
cpu: 200m
memory: 100Mi
#Container比POD多了上述两种默认值(default和defaultRequest),为什么POD不能有默认值?
#因为POD本身是逻辑的概念,里面可能包含多个容器,里面有1个容器可给默认值,多个容器不能给默认值,只能给POD的多个容器做限制,而不能给默认值。
#那么POD的设置要大到多少才能包括这么多容器containerd/docker的设置?当服务没有配置资源的一些限制的时候,会默认的去使用这里的设置(default和defaultRequest)。
max:
cpu: 2000m
memory: 1Gi
min:
cpu: 100m
memory: 100Mi
maxLimitRequestRatio:
cpu: 5
memory: 4
type: Container
#上述是对容器Container的限制
绑定命名空间test与limits-test.yaml并查询
#limits是对一个namespace而言的,在一个namespace下面,可能来设置这些限制、默认值。
#这里给命名空间test以limits-test.yaml配置文件中的内容设置默认值。
[root@node-1 2-resourse]# kubectl create -f limits-test.yaml -n test
limitrange/test-limits created
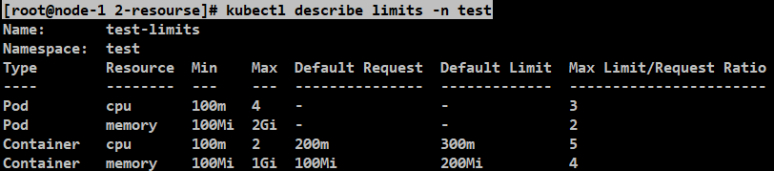
#可以查看这个命名空间下面的所有的limits。POD的default是没有的。Container是取的配置文件的默认值。配置文件中的default就是default limit。
[root@node-1 2-resourse]# kubectl describe limits -n test
原始配置文件:web-test.yaml
#这里没有对资源做限制。
#这里是测试了没有配置使用默认值的情况。
[root@node-1 2-resourse]# cat web-test.yaml
#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: test
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
查询服务详细(默认值)(接上)
[root@node-1 2-resourse]# kubectl apply -f web-test.yaml
deployment.apps/web-demo created
#看一下详细信息
[root@node-1 2-resourse]# kubectl get deploy -n test
NAME READY UP-TO-DATE AVAILABLE AGE
web-demo 1/1 1 1 26s
[root@node-1 2-resourse]# kubectl get deploy -n test web-demo -o yaml
spec:
containers:
- image: hub.mooc.com/kubernetes/web:v1
imagePullPolicy: IfNotPresent
name: web-demo
ports:
- containerPort: 8080
protocol: TCP
#发现resources空的没有
resources: {}
#设置在了POD上面
[root@node-1 2-resourse]# kubectl get pods -n test
NAME READY STATUS RESTARTS AGE
web-demo-6cd856cd4d-hrh2f 1/1 Running 0 15m
[root@node-1 2-resourse]# kubectl get pods -n test -o yaml
spec:
containers:
- image: hub.mooc.com/kubernetes/web:v1
imagePullPolicy: IfNotPresent
name: web-demo
ports:
- containerPort: 8080
protocol: TCP
resources:
#这里对应的limits-test.yaml中对应的default(limit)和defaultRequest(request)的值。
#发现POD的resources出现了namespace中设置的默认值,没有体现在deployments的配置里面,deployments还是跟原始的配置文件是保持一致的。
limits:
cpu: 300m
memory: 200Mi
requests:
cpu: 200m
memory: 100Mi
案例:测试1:10的比例不正确的情况
[root@node-1 2-resourse]# cat web-test.yaml
#deploy
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
namespace: test
spec:
selector:
matchLabels:
app: web-demo
replicas: 1
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web-demo
image: hub.mooc.com/kubernetes/web:v1
ports:
- containerPort: 8080
resources:
requests:
memory: 100Mi
cpu: 100m
limits:
memory: 1000Mi
cpu: 2000m
[root@node-1 2-resourse]# kubectl apply -f web-test.yaml
deployment.apps/web-demo configured
#发现UP-TO-DATE为0,说明web-demo还没准备好。
[root@node-1 2-resourse]# kubectl get deploy -n test
NAME READY UP-TO-DATE AVAILABLE AGE
web-demo 1/1 0 1 37m
#没发现错误
[root@node-1 2-resourse]# kubectl describe deploy -n test web-demo
#再看下yaml的文件事件,失败。
[root@node-1 2-resourse]# kubectl get deploy -n test -o yaml
#web-test.yaml中配置的比例和limits-test.yaml配置的默认比例不一致
message: 'pods "web-demo-fb97cbd44-ckjk8" is forbidden:
[cpu max limit to request ratio per Pod is 3, but provided ratio is 20.000000;
memory max limit to request ratio per Pod is 2, but provided ratio is 10.000000;
cpu max limit to request ratio per Container is 5, but provided ratio is 20.000000;
memory max limit to request ratio per Container is 4, but provided ratio is 10.000000]'
案例:测试limits超限(小于等于物理资源)
[root@node-1 2-resourse]# cat web-test.yaml
resources:
requests:
memory: 500Mi
cpu: 1000m
limits:
memory: 1000Mi
cpu: 2000m
[root@node-1 2-resourse]# kubectl apply -f web-test.yaml
deployment.apps/web-demo configured
[root@node-1 2-resourse]# kubectl get deploy -n test
NAME READY UP-TO-DATE AVAILABLE AGE
web-demo 1/1 1 1 56m
[root@node-1 2-resourse]# kubectl get deploy -n test -o yaml
#成功
message: ReplicaSet "web-demo-55f6c8cd9c" has successfully progressed.
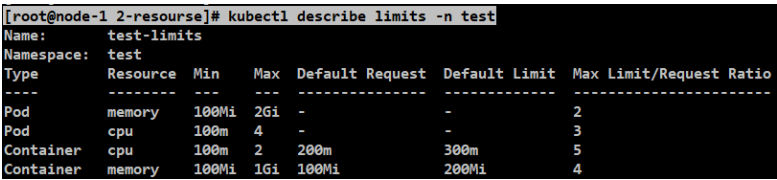
#看下limits的限额。MAX-CPU是2个,内存最大1GB是满足要求的。
[root@node-1 2-resourse]# kubectl describe limits -n test
案例:测试limits超限(大于CPU数量)
#此虚拟机CPU现在最大是2个。
[root@node-1 2-resourse]# cat web-test.yaml
resources:
requests:
memory: 2000Mi
cpu: 3000m
limits:
memory: 3000Mi
cpu: 4000m
[root@node-1 2-resourse]# kubectl apply -f web-test.yaml
deployment.apps/web-demo configured
[root@node-1 2-resourse]# kubectl get deploy -n test -o yaml
message: 'pods "web-demo-58bb9db686-tg7vj" is forbidden:
[maximum memory usage per Pod is 2Gi, but limit is 3145728k,
maximum memory usage per Container is 1Gi, but limit is 3000Mi,
maximum cpu usage per Container is 2, but limit is 4]'
方案二:资源配额resources quota
前面的案例使用limits range对namespace下的POD和容器都做了配置,保证每个服务都有一个合理的配置,同时在上一层,K8S也对namespace本身自己做了资源的限制。第一节留下来的内容。
比如多个团队,在同时使用一个集群,那么就要考虑,如何合理的分配资源,不能让一个团队把资源沾满了,别的团队就没法使用了。
资源配额resources quota就是来解决这个问题,可以给每个namespace做各种维度的限制,也是一个配置文件的形式存在的。
原始配置文件: compute-resource.yaml与object-count.yaml
[root@node-1 2-resourse]# cat compute-resource.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: resource-quota
spec:
hard:
pods: 4
requests.cpu: 2000m
requests.memory: 4Gi
limits.cpu: 4000m
limits.memory: 8Gi
#除了对CPU和memory的限制以外,还有更多的资源类型的限制。
#当然也可以跟上面的配置文件的内容配置到同一个配置文件中,当然功能有区别。
#这个kind也是ResourceQuota,也可以跟上面的属性配置在上述同一个文件中。
功能还是有区别的。
[root@node-1 2-resourse]# cat object-count.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
spec:
hard:
#在这个命令空间下,最多有10个configMap,可以有4个pvc,其他属性同理。
configmaps: 10
persistentvolumeclaims: 4
replicationcontrollers: 20
secrets: 10
services: 10
#可以对K8S的资源做一下数量方面的限制,这也是资源配额的另外一些功能。
[root@node-1 2-resourse]# kubectl apply -f compute-resource.yaml -n test
resourcequota/resource-quota created
#记得加-n命名空间,默认创建命名空间。
[root@node-1 2-resourse]# kubectl apply -f object-count.yaml -n test
resourcequota/object-counts created
#上述这俩对象就是quota类型。
查询资源是否饱和
[root@node-1 2-resourse]# kubectl get quota -n test

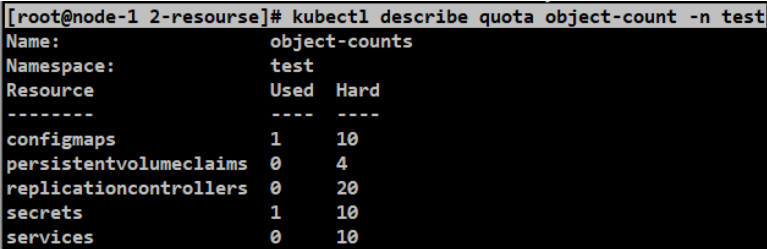
#可以看到当前使用的数量和限制数量。看资源是否饱和了。
[root@node-1 2-resourse]# kubectl describe quota object-count -n test
案例:调整副本数
[root@node-1 2-resourse]# cat web-test.yaml
#从1改成5。上述限制数是4个。
replicas: 5
[root@node-1 2-resourse]# kubectl apply -f web-test.yaml
deployment.apps/web-demo configured
[root@node-1 2-resourse]# kubectl get deploy -n test
#这里只成功了两个,说明POD确实是达到了限制。
NAME READY UP-TO-DATE AVAILABLE AGE
web-demo 2/5 0 2 129m
[root@node-1 2-resourse]# kubectl get deploy -n test -o yaml
message: 'pods "web-demo-58bb9db686-tg7vj" is forbidden:
[maximum memory usage per Pod is 2Gi, but limit is 3145728k,
maximum memory usage per Container is 1Gi, but limit is 3000Mi,
maximum cpu usage per Container is 2, but limit is 4]'
[root@node-1 2-resourse]# kubectl get all -n test -o wide
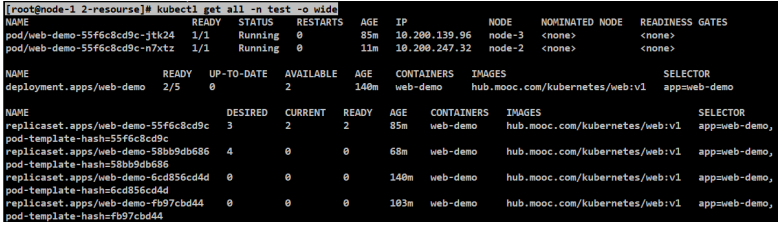
#看下resource-quota的资源的量是否到头了
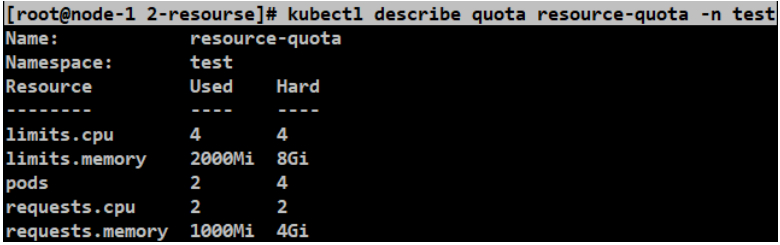
[root@node-1 2-resourse]# kubectl describe quota resource-quota -n test
#这里看到虽然POD没满,但是根据现有配置的资源量,已经不能再运行其他的资源了。同样,其他的属性值达到限制,那么也不会被调度。
POD驱逐策略
上述各种的配额都配置好了,从container,pod到namespace,是否会出现万无一失,不会出现资源相关的问题了呢?NO!当不停的调度新的服务,最终很有可能有一些节点会达到饱和,一些服务实际使用的内存大于requests的时候,就有可能导致当前节点的物理内存不足,从而达到系统设置的阈值,内核就要开始杀进程,甚至可能会把容器(docker/containerd)给杀掉,严重影响了系统的稳定性。
K8S可能是想到了这个问题,加入了POD的驱逐策略来保证系统的稳定性。
每个节点都跑着了一个kubelet,它会持续的去监控主机资源的使用情况,一旦资源紧缺的情况,就会主动的停止一个或多个POD来回收一些资源。
但如何来判断什么时候进行驱逐,如果驱逐的话,驱逐谁呢?K8S支持了一些参数,让我们自己去调整驱逐的策略。
K8S的POD驱逐策略是非常重要的,是跟K8S的稳定性是息息相关的,在生产环境可以说是必备的配置。

第1个参数,软阈值,当节点的可用内存小于1.5Gi的时候
第2个参数,当内存持续1m30s都小于1.5Gi的时候就实行驱逐
之所以说是soft,并不是说发现就马上去驱逐,而是有一个时间。上述俩参数结合在一起使用。
最后一个参数,当上述条件一旦满足的时候,立刻开始驱逐,内存小于100Mi的时候,磁盘小于1Gi的时候,剩余的inode,节点小于5%,都会立刻的去执行驱逐策略。

删除没用的镜像,释放一些磁盘空间。
如果回收的资源足够,那么磁盘的压力就会解除,否则就会按照多种优先级(完全可靠的、基本可靠的、不可靠的等)开始驱逐,比如inode资源短缺,就会在同级别的POD中选择占用资源最多的POD来驱逐。磁盘等也是一样的。

Kubelet首先会在不可靠的POD中找到占用内存资源最大的POD,把它干掉,如果没有不可靠的POD可以删除,那么就会去基本可靠的POD中,先去找到实际使用的内存大于requests的POD,找到这些,超过的越多就优先被删除,如果大家都没有超过requests,那么就会直接去找占用内存最大的应用,把它删除,如果这样还没解决问题,那么最后实在不行,会去删除最可靠的POD,删除的过程,跟基本可靠的POD的策略是一样的。
POD的驱逐策略是非常重要的一块,因为跟K8S的稳定性是息息相关的。在生产环境是非常重要的配置。
比如可以改一个WEB服务,修改一个吃内存的controller,可以通过访问URL,传一个memory参数,让其在java内存中直接占用这么大的内存,这就非常贴近这个案例了。
标题:Kubernetes(九)资源对象(9.3)Resources---多维度集群资源管理(下)
作者:yazong
地址:https://blog.llyweb.com/articles/2022/11/19/1668799894503.html