11.2.1 数字关键词的散列函数构造
目的

直接定址法
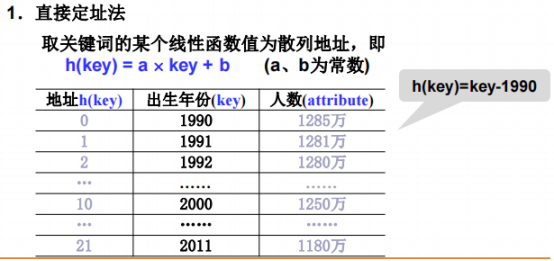
把散列函数设计成一个线性函数。
关键词是年份,把值映射成0-21的地址空间。
这里只有22个元素。
(最常用)除留余数法
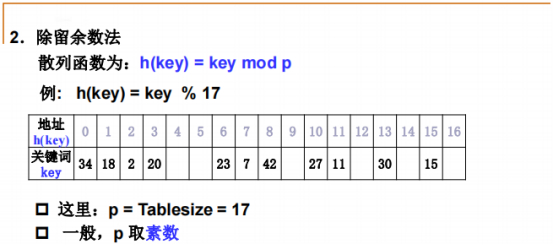
把关键词进行求余计算,把一个大的整数转换成一个小的整数,相当于散列表的地址。
为了散列表映射均匀,一般会把散列表的总数P设置成素数。
数字分析法
关键词可能有许多位数组成,每一位在对象中的变化情况不同,有的某一位可能一直都是不动的,有的某些位会随机变化。
数字分析法希望分析出对象的关键字在每一位上的表现,把这些能够随机变化的这些位取出来组成地址,达到映射均匀的目的。
====手机号案例

对于同一地区来说,手机号前几位可能都差不多,变化最大的是后四位,可以把手机号的后四位作为地址。

最终获得地址。
====身份证号案例
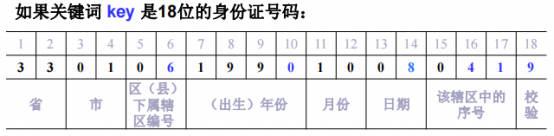
身份证号中的每一位都有特殊含义,蓝色数字是变化比较大的,提出来。
[6]-6:区县变化大。
[10]-0:生日都是199X年的,最后一位变化大。
[14]-8:日期十位变化大。
[16]-4:辖区序号变化大。
[17]-1:辖区序号变化大。
[18]-9:数字或字符变化大。

计算h1(key)拿到前五位60841组成五位数(十进制)。
计算h(key)再把h1(key)组合进来。
折叠法

总共8位,从后往前,每段拆成3位,不够前面补0。
最后取计算结果的后三位作为地址。
也是希望结果能被更多的位数所影响。
平方取中法
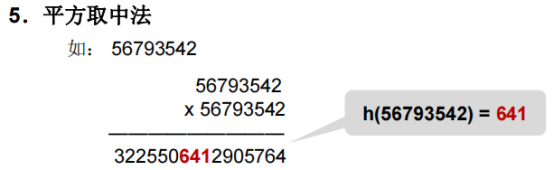
希望计算的函数值,每一位都能被影响,即每一位的变化都能影响到最后的函数结果值,比如尾数。
取平方值的中间的三位数,也是希望结果能被更多的位数所影响。
11.2.2 字符串关键词的散列函数构造

把字符串对象映射为整数,每一个字符是一个ASCII编码,所有整数相加,求余得到散列值。
但这样的方法也会有很多冲突。
更致命的问题,ASCII主要用到7位,编码范围0-127,比如变量名是10位,那么每个字符值的变化范围是0-1270,但变量名的变化范围更广大,如果用一个很窄的值计算结果来对付一个很广的变量名的范围,那么这样的哈希函数就很容易产生聚集。

比如abcde,取前面3个字符,通过27进制来计算。
用27,是因为26个字符之后可能会有空格,所以可能有27个字符。
这样仍然会产生冲突,因为变量名很长,前三位是一样的。
另外,可能会造成地址空间浪费,三个字符变化是26的三次方,实际统计前三位一般出现的情况是3000种,实际上考虑26的三次方会导致地址空间浪费。
进一步考虑,不只考虑前三个字符组合,而是把所有的字符都组合,3、4、5、6位等都考虑进去。

比如把字符abcde的序列,考虑32进制来计算。

级数求和:((((a*32+b)*32+c)*32+d)*32+e),这样可以减少乘法的次数,这里4次,原来10次。
更巧妙的方法:x << 5 ,左移5位就是X * 32。
源码:
第1次循环key不等于0,指向”abcde”中的”a”,0<<5=0,即h1=0 + a。
第2次循环key不等于0,指向”abcde”中的”b”,即h2=h1<<5 + b。
依次处理,最终结果h直接求余即可。
标题:(数据结构)第十一讲-散列查找(11.2 散列函数的构造方法)
作者:yazong
地址:https://blog.llyweb.com/articles/2023/10/22/1697984883679.html