11.3.1 开放定址法
冲突处理(开放地址法、链地址法)

把同一位置的冲突对象组织在一个链表中,将来计算出来这个地址,地址指向这个单向链表,然后去找到这个”把同一位置的冲突对象组织在一个链表”的方法,叫做链地址法。

寻找地址是说:看看位置有没有空,空就放进去,不空就按规则计算下一个位置。

首先散列函数算出一个初始要存放的位置,当第一次发生冲突,要找下一个位置的时候,在原来散列函数的基础上加上一个di,当i=1,所以加d1,di是一个偏移量,是探测次数的函数,又根据di的不同设计方法又分为下述三种方法。

线性探测

把di函数设计成一个线性函数,一开始算出的散列函数,在这个基础上发现有冲突,那么就加di,第一次探测加1,以后依次在原来的基础上+2,+3,实际效果是,有冲突就继续一个个往后找下一个位置。
发现问题,提出”平方探测”。
平方/二次探测(上述优化)

不是在一个方向去探测。
比如散列函数找到的位置H,发现有冲突+1平方,再有冲突就到h-1平方位置去找,于是h+2平方位置、h-2平方位置,每次是在原来基础(原位置)上偏移量升级,找位置简单来说就是:+1^2,-1^2,+2^2,-2^2这个不断找的过程,由于不管是加还是减,位置的范围可能超出了散列表地址范围之外,这个时候通过求余就计算回来了。
双散列(上述优化)

把di设计成i,乘以散列函数,叫双散列。
两个散列函数:
第1个散列函数作为最早即时找到的位置。
第2个散列函数用来计算偏移量,在原来基础上再偏移多少找到相应位置。
11.3.2 线性 /一次探测
散列计算(地址、冲突与聚集)

线性探测在原来基础上,产生一个增量序列,这个增量序列就是1234,在原来位置找下一个下一个。
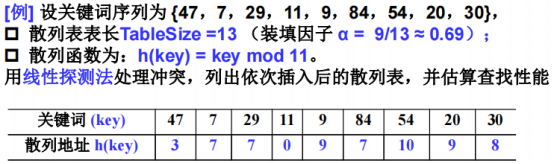
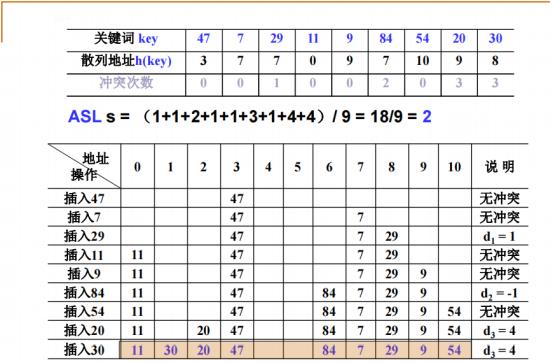
先把序列中的9个数装入散列数组,采用线性探测,分别对11求余,算出散列地址,逐个放入散列表中。

(某位置被占用后,很容易在它的周围产生新的聚集。)
按序插入:
47实际插入散列地址:3。
7实际插入散列地址:7。
29实际插入散列地址:8,计算散列地址7,因为冲突找下一个位置+1,冲突次数1。
11实际插入散列地址:0。
9实际插入散列地址:9。
84实际插入散列地址:10,计算散列地址7,因为冲突找下一个位置+3,冲突次数3。
54实际插入散列地址:11,计算散列地址10,因为冲突找下一个位置+1,冲突次数1。
20实际插入散列地址:12,计算散列地址9,因为冲突找下一个位置+3,冲突次数3。
30实际插入散列地址:1,计算散列地址8,因为冲突找下一个位置+6,冲突次数6。
线性探测的问题:当散列值有冲突集中在某些位置的时候,在这个位置会形成聚集,冲突位置越来越多。
散列表查找性能分析(ASLs/ASLu)

成功平均查找长度(ASLs):在散列中的对象最后找到了,找元素的次数的平均值计算出来即可。
不成功平均查找长度(ASLu):不在散列中的元素去找。
散列表查找性能-整数例子

这里在已经计算好的散列表中计算下述内容。
====成功平均查找长度(ASLs)的计算(只计算存在的元素,空位置不计算):
冲突次数是0,意味着没冲突,比较次数是1。
冲突次数是6,意味着6次查找冲突,只有最后一次查找到空位置成功,比较次数是7。
所有元素比较次数相加/KEY个数即可。
====不成功平均查找长度(ASLu)的计算(只计算不存在的元素,如何插入空位置):
关键词分类11种(0123456789)。
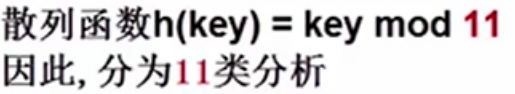
(根据散列函数或散列值把对象分类后计算)
不成功的并且不在这个散列表中的元素很多,不可能再用枚举法一个个去算,把不在散列表中的所有元素分成若干种类型,一类类的去算,只要按照这个查找过程,哈希值是一样的,那么元素的查找过程和查找次数也一样。
这里的个人诀窍:把KEY当做散列表的索引,类型有0123456789,11种,长度11,按照上述散列表的内容,查找插入某索引位置的元素往右找,找到离此索引位置不空的位置需要比较的次数即可。
比如(把下述的AB字母当成数字即可,这里是求余后的值):
注意:插入的字符串要跟上述图形中已存在的索引表对比,有元素的索引,没有元素的索引。
元素A插入索引0,但是有元素,算上与被插入索引原值KEY的比较1次,再往右比较2次才找到索引2空位置,总共比较3次。
元素B插入索引1,同理,比较2次。
元素C插入索引2,本身就在索引2,索引2空位置,与自身比较,总共比较1次。
...
元素H插入索引7,但是有元素,算上与被插入索引原值KEY的比较1次,再往右比较5次到头了,需要再倒过来从索引0开始比较到索引2比较3次,索引2空位置,总共比较9次。
剩余元素同理。
散列表查找性能- 字符串例子

散列表大小26,散列函数设计成取第一个字符的位置。
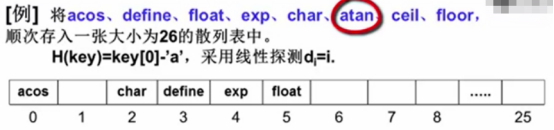
当存完前五个字符串后,剩余字符串都有冲突。
比如:
字符串”atan”,计算散列表位置0,可放入到散列表空位置1,比较次数2。
字符串”ceil”,计算散列表位置2,可放入到散列表空位置6,比较次数5。
字符串”floor”,计算散列表位置5,可放入到散列表空位置7,因为位置6已经存入,所以比较次数3。
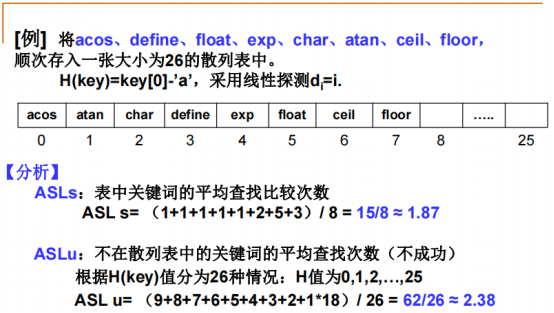
====成功平均查找长度(ASLs)的计算(只计算存在的元素,空位置不计算):
第一行蓝色标记的所有字符串,前五个,分别比较1次,后三个字符串,分别比较2次、5次、3次,除以总元素个数。
====不成功平均查找长度(ASLu)的计算(只计算不存在的元素,如何插入空位置):
分成26种情况,分成abc...xyz打头的情况,这种情况认为是等概率的。
26种打头的字符串,插入到对应具有26个索引的索引表中。
比如a打头的字符串插入索引0,b打头的字符串插入索引1,z打头的字符串插入索引25。
注意:插入的字符串要跟上述图形中已存在的索引表对比,0-7已经有元素,8-25还没有元素。
比如:
“aXX”插入索引0,但是有元素,算上与被插入索引原值KEY的比较1次,再往右比较8次才找到索引8空位置,总共比较9次。
“bXX”插入索引1,但是有元素,算上与被插入索引原值KEY的比较1次,再往右比较7次才找到索引8空位置,总共比较8次。
...
到索引7同理。
后18个元素的当前位置就是空,与自身比较,各自比较1次,总共比较18次。
上述比较次数相加,除以分类个数。
11.3.4 平方 /二次探测法

偏移量是通过(有符号-个人添加)i^2计算而来。
成功平均查找长度(ASLs)
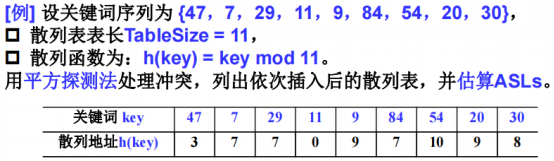
计算散列地址的方式跟线性探测中的例子一样,都是对KEY求余,这里依然是对11求余。
按序插入:
47实际插入散列地址:3,无冲突。
7实际插入散列地址:7,无冲突。
29实际插入散列地址:8,计算散列地址7,因为冲突找下一个位置+1^2,冲突次数1。
11实际插入散列地址:0,无冲突。
9实际插入散列地址:9,无冲突。
84实际插入散列地址:6,计算散列地址7,因为冲突找下一个位置+1^2,8位置依然冲突,执行-1^2,找到位置6空,冲突次数2。
54实际插入散列地址:10,无冲突。
20实际插入散列地址:12,计算散列地址9,因为冲突找下一个位置+1^2,10位置依然冲突,执行-1^2,8位置依然冲突,执行2^2,找到位置2空,冲突次数3。
30实际插入散列地址:1,计算散列地址8,因为冲突找下一个位置+1^2,9位置依然冲突,执行-1^2,7位置依然冲突,执行2^2,找到12空,冲突次数3。
有空间是否能找到(4K+3素数)


(比如7、11、19等素数,可以在理论上证明此结论。)
线性探测:某位置有冲突时,继续往后面不断的找,按照这样的策略,只要表有空,就一定能找到空位,并把元素放进去。
平方/二次探测法:跳着找位置,可能有空位置,可就是找不到,有可能会有此问题。
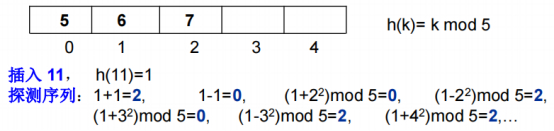
此结果就在0202之间跳来跳去,这个例子后面没继续算下去,跳来跳去始终找不到空位置。

双散列探测法(良好效果:公式、素数)

偏移量设计成
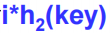
的形式,往后的偏移量变成比如2h^2、3h^2等,但不能为0,为0就是没有偏移量,就跟原来的值一样。
有经验证明,可以根据上述要求设计成上述的公式,达到不错的效果。
再散列(装填因子->查找效率)
散列表一般是个数组,不断地把元素往数组中存储,当散列表中的元素过多时,比如已经90%被装满,那此时的查找效率就会下降,装填因子也会太高,冲突就会不断增加。

原来散列表的大小,比如是11,后来装到9个元素,发现冲突太多,装载因子太大,为提高效率,那么把散列表rehash扩大一倍,表变成23散列大小,要注意,把散列表从11变成23的时候,原散列表中的元素并不是直接拷贝到分量里去的,而是需要重新计算。

比如把原9个元素重新按照表变成23散列大小重新计算,再把9个元素一个个拷贝进去,这个是再散列。
装填因子在0.5和0.85之间已经是很大的了,最好控制在0.5以内,超过0.85肯定是没法接受的。
11.3.6 分离链接法 /链地址法

一个位置上有冲突的所有关键词都放在同一个单链表中,各放置在各自的单链表中,并不是放置在数组中。
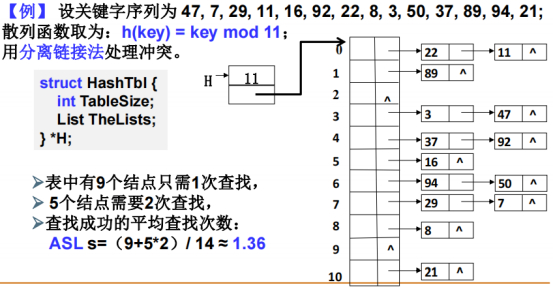
结构中有个指针指向一个数组,这个数组并不是原来存放元素的了,它是一个指针指向一个单链表,对11求余,比如22、11的哈希值(位置)等于0,那么数组[0]指向这个余数为0的单链表,这个单链表中就只存哈希值(位置)等于0的元素。
没有元素的数组下标用^来标记,代表这个位置没元素,是NULL空指针,当然也不会指向任何一个单链表(不会初始化)。
源码(一)创建开放定址法的散列表(模板、散列地址)
#include<stdio.h>
#include<math.h>
/*
散列查找-创建开放定址法的散列表
*/
int main(void){
return 0;
}
/* 允许开辟的最大散列表长度 */
#define MAXTABLESIZE 100000
/* 关键词类型用整型 */
typedef int ElementType;
/* 散列地址类型 */
typedef int Index;
/* 数据所在位置与散列地址是同一类型 */
typedef Index Position;
/* 散列单元状态类型,分别对应:有合法元素、空单元、有已删除元素 */
typedef enum {Legitimate, Empty, Deleted} EntryType;
/* 散列表单元类型 */
struct HashEntry{
/* 存放元素 */
ElementType Data;
/* 单元状态 */
EntryType Info;
}
/* 散列表类型 */
typedef struct TblNode *HashTable;
/* 散列表结点定义 */
struct TblNode{
/* 表的最大长度 */
int TableSize;
/* 存放散列单元数据的数组 */
Cell *Cells;
}
/* 返回大于N且不超过MAXTABLESIZE的最小素数 */
int NextPrime(int N){
/*从大于N的下一个奇数开始 */
int i, p = (N % 2) ? N + 2 : N + 1;
while(P <= MAXTABLESIZE){
for( i = (int)sqrt(q); i > 2; i--){
if(!(p % i)){
/* p不是素数 */
break;
}
}
/* for正常结束,说明p是素数 */
if(i == 2){
break;
}else{
/* 否则试探下一个奇数 */
p += 2;
}
}
return p;
}
HashTable CreatTable(int TableSize){
HashTable H;
int i;
H = (HashTable)malloc(sizeof(struct TblNode));
/* 保证散列表最大长度是素数 */
H->TableSize = NextPrime(TableSize);
/* 声明单元数组 */
H->Cells = (Cell *)malloc(H->TableSize * sizeof(Cell));
/* 初始化单元状态为“空单元” */
for( i = 0; i < H->TableSize; i++){
H->Cells[i].Info = Empty;
}
return H;
}
源码(二)平方探测法的 散列表实现(初始化、查找与插入 )
#include<stdio.h>
#include<math.h>
/*
散列查找-平方探测法的散列表实现(初始化、查找与插入)
*/
int main(void){
return 0;
}
typedef struct HashTbl *HashTable;
/*设计成一个结构*/
struct HashTable{
int TableSize;
/*
给每个元素做Info标记,比如空、删除.
删除是逻辑删除,仅做标记使用,判断是否空位,以防是否空位置误判,
如果有删除标记,那么插入时直接替换掉即可,而不影响查找过程.
*/
/*
在开放地址散列表中,删除操作要很小心.
通过只能"懒惰删除",即需要增加一个"删除标记Deleted",而不是真正的删除它.
以便查找时不会"断链",其空间可以在下次插入时重用.
*/
Cell *TheCells;
} H;
/*散列表初始化*/
HashTable InitializeTable(int TableSize){
HashTable H;
int i;
if(TableSize < MinTableSize){
Error("散列表太小");
return NULL;
}
/*分配散列表数组*/
H = (HashTable)malloc(sizeof(struct HashTbl));
if(H == NULL){
FatalError("空间溢出!");
}
/*希望散列表的大小是个素数*/
H->TableSize = NextPrime(TableSize);
/*分配散列表Cells*/
H->TheCells = (Cell *)malloc(sizeof(Cell) * H->TableSize);
if(H->TheCells == NULL){
FatalError("空间溢出!");
}
for(i = 0; i < H->TableSize; i++){
/*初始化每个元素都是空的*/
H->TheCells[i].Info = Empty;
}
return H;
}

/*平方/二次探测查找*/
Position Find(ElementType Key, HashTable H){
Position CurrentPos, NewPos;
int CNum;
/*
判断计算下一个哈希位置是加还是减,
记录冲突次数.
*/
Cnum = 0;
/*
哈希函数计算的新位置
±i^2
*/
NewPos = CurrentPos = Hash(Key, H->TableSize);
while(H->TheCells[NewPos].Info != Empty && H->TheCells[NewPos].Element != Key){
/*
判断冲突的奇偶数
CNum第一次等于1
*/
/*奇数*/
if(++CNum % 2){
/*CNum=奇数:+i^2*/
NewPos = CurrentPos + (CNum + 1)/2 * (CNum + 1)/2;
/*上述不断的+可能超出tablesize的范围,不断减回来让NewPos位于0与TableSize之间.*/
while(NewPos >= H->TableSize){
NewPos = NewPos - H->TableSize;
}
}
/*偶数*/
else{
/*CNum=偶数:-i^2*/
NewPos = CurrentPos - (CNum)/2 * (CNum)/2;
/*上述不断的-可能超出tablesize的范围,不断加回来让NewPos位于0与TableSize之间.*/
while(NewPos < 0){
NewPos = NewPos + H->TableSize;
}
}
}
/*返回找到的位置,并不是属于被别人占用的位置.*/
return NewPos;
}
/*平方/二次探测插入*/
void Insert(ElementType Key, HashTable H){
Position Pos;
Pos = Find(Key, H);
/*位置不是被占用状态:空位或者被删除状态位置*/
if(H->TheCells[Pos].Info != Legitimate){
/*确认在此插入*/
H->TheCells[Pos].Info = Legitimate;
H->TheCells[Pos].Element = Key;
}
}
源码(三)分离链接法的散列表实现 (创建、查找、插入、销毁)
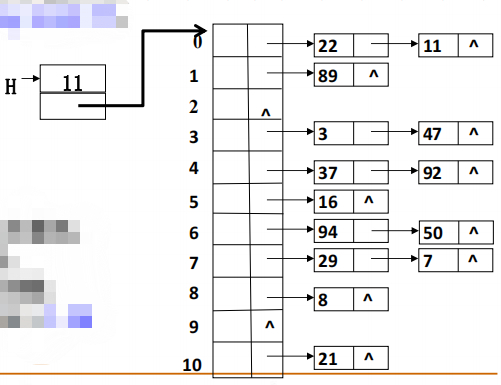
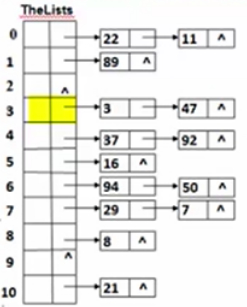
(注意:插入链表的新结点总是插入到链表的头元素位置中。)
有个指针指向数组的某个位置,这个位置的指针指向一个单向链表,把相同哈希函数值的元素都放在这个单向链表中,没元素的位置用”^”标记。
#include<stdio.h>
#include<math.h>
/*
散列查找-分离链接法的散列表实现(创建、查找、插入、销毁)
*/
int main(void){
return 0;
}
/* 关键词字符串的最大长度 */
#define KENLENGTH 15
/* 关键词类型用字符串 */
typedef char ElementType[KENLENGTH + 1];
/* 散列地址类型 */
typedef int Index;
/******** 以下是单链表的定义 ********/
typedef struct LNode *PtrToLNode;
struct LNode{
ElementType Data;
PtrToLNode Next;
}
typedef PtrToLNode Position;
typedef PtrToLNode List;
/******** 以上是单链表的定义 ********/
/* 散列表类型 */
typedef struct TblNode *HashTable;
/* 散列表结点定义 */
struct TblNode{
/* 表的最大长度 */
int TableSize;
/* 指向链表头结点的数组 */
List Heads;
}
HashTable CreateTable(int TableSize){
HashTable H;
int i;
H = (HashTable)malloc(sizeof(struct TblNode));
/* 保证散列表最大长度是素数*/
H->TableSize = NextPrime(TableSize);
/* 以下分配链表头结点数组 */
H->Heads = (List)malloc(H->TableSize * sizeof(struct LNode));
/* 初始化表头结点 */
for(i = 0; i < H->TableSize; i++){
H->Heads[i].Data[0] = '\0';
H->Heads[i].Next = NULL;
}
return H;
}
Position Find(HashTable H, ElementType Key){
Position P;
Index Pos;
/* 初始散列位置,代表了在数组中的位置. */
Pos = Hash(Key, H->TableSize);
/* 从该链表的第1个结点(获得链表头)开始,指向了单向链表的第一个元素. */
P = H->Heads[Pos].Next;
/* 当未到表尾,并且Key未找到时 */
while(P && strcmp(P->Data, Key)){
/*
只要P不等于NULL并且P指向的元素和要找的元素KEY不相等(strcmp是否相等判断,0是相等),
就一个个往后找,能找到就是有元素.
*/
P = P->Next;
}
/* 等上述循环退出,此时P或者指向找到的结点,或者为NULL */
return P;
}
bool Insert(HashTable H, ElementType Key){
Position P, NewCell;
Index Pos;
P = Find(H, Key);
/* 关键词未找到,可以插入 */
if(!P){
NewCell = (Position)malloc(sizeof(struct LNode));
strcpy(NewCell->Data, Key);
/* 初始散列位置 */
Pos = Hash(Key, H->TableSize);
/* 将NewCell插入为H->Heads[Pos]链表的第1个结点 */
NewCell->Next = H->Heads[Pos].Next;
H->Heads[Pos].Next = NewCell;
return true;
}else{
/* 关键词已存在 */
printf("键值已存在");
return false;
}
}
/*释放散列表的空间*/
void DestroyTable(HashTable H){
int i;
Position P, Tmp;
/* 释放每个链表的结点 */
for(i = 0; i < H->TableSize; i++){
P = H->Heads[i].Next;
while(P){
Tmp = P->Next;
free(P);
P = Tmp;
}
}
/* 释放头结点数组 */
free(H->Heads);
/* 释放散列表结点 */
free(H);
}
标题:(数据结构)第十一讲-散列查找(11.3 冲突处理方法)
作者:yazong
地址:https://blog.llyweb.com/articles/2023/10/22/1697985966198.html